Questo argomento è stato trattato in systemsAndNetworksSecurity
Process Isolation: introduzione
Process Isolation: definizione
La process isolation è una misura di sicurezza che separa i singoli processi in esecuzione su un sistema per evitare che interagiscano tra di loro.
Questo meccanismo viene realizzato impendendo ad un processo A di scrivere su un processo B, sfruttando il meccanismo del virtual address space (spazio degli indirizzi virtuale). I processi possono ancora comunicare tramite i meccanismi di IPC (InterProcess Communication).
Linux Kernel Isoltaion (inc. LXC, Linux Containers)
Linux Containers (LXC) è un metodo di virtualizzazione a livello del sistema operativo per eseguire più sistemi Linux isolati (containers) su un host usando un unico kernel Linux.
Il kernel Linux fornisce le seguenti funzionalità:
- CGroups: permettono la limitazione e l’assegnazione di priorità alle risorse senza avviare macchine virtuali;
- Kernel namespace: permettono il completo isolamento della vista dell’ambiente operativo di un’applicazione, inclusi l’albero dei processi, il networking, gli id utenti e il file system montato.
LXC combina i cgroups del kernel e supportano namespace isolati per fornire un ambiente isolato alle applicazioni.
Change root (chroot)
Mediante l’utilizzo del change root, i processi sono limitati ad accedere solamente i file all’interno della nuova directory. In particolare, quando si avvia il sistema operativo, tutti i processi si riferiscono alla root originale (/) dell’albero del filesystem; con l’uso di chroot, è possibile cambiare la root directory per uno specifico processo e i suoi figli.
Questo comando si occupa di creare un ambiente ristretto, detto chroot jail o jailed directory e il jailed process non può risalire al root originale.
I casi d’uso per il comando chroot sono:
- la creazione di un ambiente isolato (sandbox) per eseguire applicazioni untrusted;
- operazioni di ripristino del sistema;
- test dell’ambiente;
- separazione dei privilegi;
- riparazione o reinstallazione del bootloader;
- installazione dell’OS da zero.
Creazione di una root jail
L’utilizzo di base di chroot è il seguente:
chroot /path/to/new/root commandCreando una root jail, è possibile che alcuni comandi (non built-in della shell) non abbiano a disposizione tutte le dipendenze che sono necessarie per l’esecuzione; il flusso di utilizzo tipico diventa allora:
mkdir $HOME/jail
mkdir -p $HOME/jail/{bin, lib64}
cd $HOME/jail
cp -v /bin/{bash, ls} $HOME/jail/bin
# Listing dependencies
ldd /bin/bash
cp -v libraries/displayed/by/above/command $HOME/jail/lib64
sudo chroot $HOME/jail /bin/bashKernel Namespaces
Namespace: definizione
I namespaces sono una funzione del kernel Linux che partiziona le risorse del kernel in modo tale che un insieme di processi veda solamente un insieme di risorse, mentre un altro insieme di processi vede un diverso insieme di risorse.
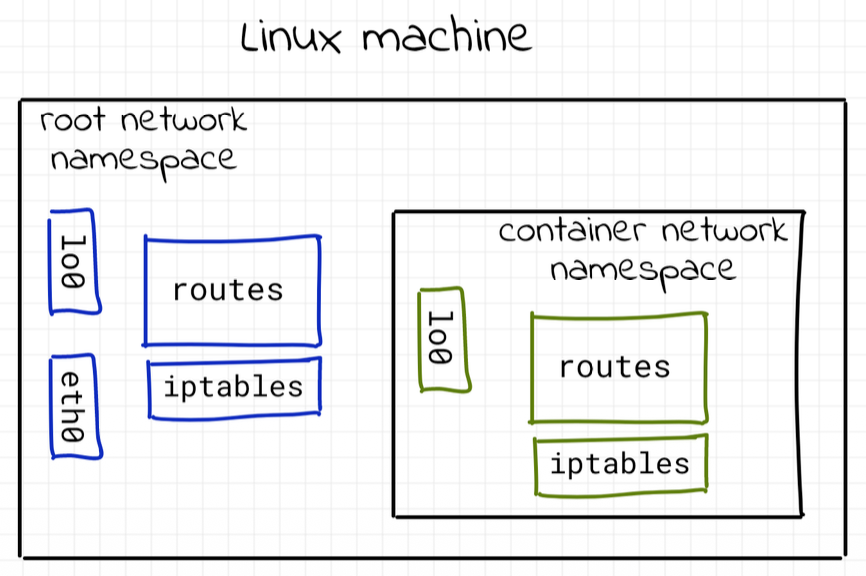
I namespace sono dei blocchi fondamentali dei container Linux e consentono l’isolamento dei processi gli uni dagli altri. Due o più namespace possono esistere sullo stesso computer fisico e possono condividere l’accesso a certe risorse o averne l’accesso esclusivo.
I tipi di namespace più in uso:
- process isolation (PID namespace);
- network interfaces (net namespace);
- Unix Timesharing System (UTS namespace);
- user namespace;
- mount (mnt namespace);
- InterProcess Communication (IPC;
- Cgroups.
Namespace API
L’API per il namespace del kernel Linux consiste di 3 principali system calls:
clone: crea un nuovo processo figlio, in modo simile allaforke permette al processo figlio di condividere parti del contesto di esecuzione del processo chiamate come lo spazio di memoria, la tabella dei file descriptors e la tabella dei signal handlers;unshare: permette a un processo di disassociare parti del suo contesto di esecuzione che sono attualmente condivise con gli altri;setns: riassocia il thread chiamante con il file descriptor del namespace fornito (viene tipicamente usata per unirsi a un namespace esistente).
Oltre alle syscall disponibili, il filesystem /proc fornisce file aggiuntivi e correlati ai namespace. Da Linux 3.8, infatti, ogni file in /proc/$PID/ns è un link che può essere usato come handle per compiere operazioni (come setns(2)) al namespace di riferimento.
User namespace: capabilities
Il modo principale con cui Linux gestisce i permessi è attraverso l’implementazione degli utenti. In aggiunta agli utenti (e soprattutto con lo scopo di fornire più granularità alle operazioni che, altrimenti, sarebbero svolte con root e quindi con la possibilità di compiere qualsiasi operazione), vengono introdotte le capabilities.
I processi privilegiati (quelli che hanno effective user ID pari a 0) possono saltare tutti i controlli sui permessi del kernel, mentre i processi non privilegiati sono soggetti a tutti i controlli sui permessi, basati sulle credenziali del processo (cioè utente e gruppo).
In questo contesto, le capabilities sono dei privilegi (tipicamente appartenenti a root) granulari che possono essere assegnati o rimossi a un processo; più capabilities formano un capabilities set, che definisce quali capabilities un processo o un thread possiede o può possedere.
Solo due di questi sono rilevanti:
- effective: il kernel verifica ogni azione privilegiata e decide se permettere o non permettere una system call. Se un thread o file possiede l’effective capability, è permesso svolgere l’azione correlata all’effective capability;
- permitted: le permitted capabilities non sono ancora attive. Se un processo ha certe permitted capabilities, significa che il processo può scegliere di elevare i suoi privilegi in effective privileges.
Per capire quali capabilities un process può avere, si può usare:
getcaps $PIDLe capabilities sono legate a un namespace utente (user namespace). Ogni namespace ha il proprio insieme di capabilities che si applica solo al proprio namespace.
Creazione di un user namespace
Lo user namespace è un modo per un container di avere un diverso insieme di permessi rispetto al sistema stesso; ogni container eredita i suoi permessi dall’utente che ha creato il nuovo user namespace.
La creazione di un nuovo namespace avviene col comando:
unshare -UIl comando include una variabile PS1 che cambia la shell in modo che sia più semplice stabilire in che namespace la shell è attiva:
PS1='\u@app-user$ ' unshare -U nobody@app-user$Di default, non c’è nessun user ID mapping che avviene e, quindi, il namespace utilizza le regole del sistema per determinare come gestire un utente non definito. È, però, possibile avere un mapping automatico, specificando:
PS1='\u@app-user$ ' unshare -urLo user namespace governa tutti i namespace: le capabilities di un namespace sono direttamente correlate alle capabilities del suo user namespace genitore. L’originale e root user namespace possiede tutti i namespace su un sistema.
Se un processo in esecuzione nel net namespace è eseguito come root, può impattare tutti gli altri processi posseduti dal root user namespace; tuttavia, anche se uno user namespace non privilegiato permette a nuovi user namespace di accedere alle risorse in altri namespace, questi non possono alterarli (non possedendoli). Ad esempio, un metre un processo in un namespace non privilegiato può pingare un IP (funzionalità offerta dal net namespace), non può cambiare la configurazione di rete dell’host.
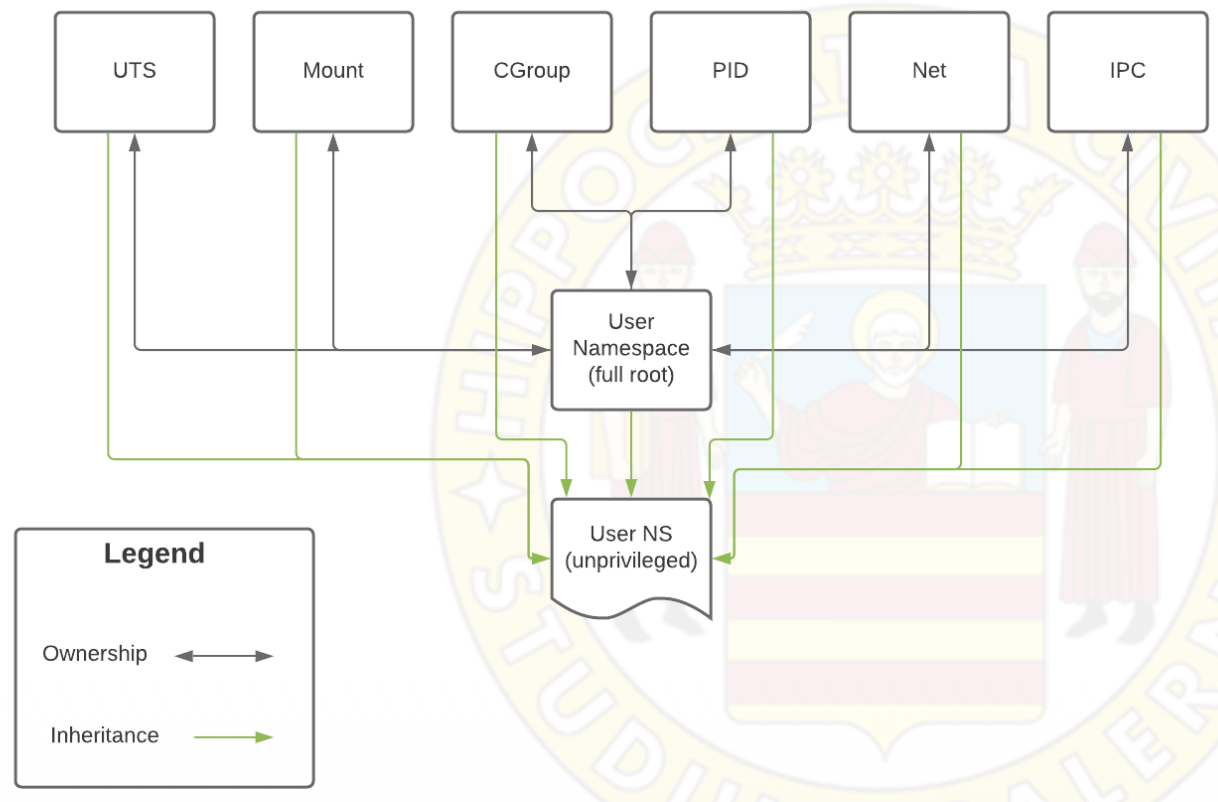
mnt namespace
Di default, se si cresse un nuovo mount namespace con:
unshare -mil sistema rimarrebbe per lo più inalterato e non confinato.
Questo perché, quando si crea un nuovo mount namespace, una copia dei mount point del namespace genitore viene creata in un nuovo mount namespace.
Configurazione sicura di un mount namespace (chown)
La configurazione appropriata per la creazione di un namespace sicuro inizia con il cambio della proprietà della directory fakeroot verso l’utente del container (container-user), in modo da mappare l’utente root del container con l’utente container-user al di fuori del container. Questa operazione consente ai processi all’interno del namespace di credere che abbiano tutte le capabilities necessarie per modificare i file (all’interno del computer), mentre il filesystem dell’host impedirà a container-user di modificare i file di sistema (AlpineLinux per il prossimo esempio). Un esempio1:
# crea la variabile d'ambiente con la directory del container
export CONTAINER_ROOT_FOLDER=/container_practice
# crea effettivamente la cartella
# mkdir -p crea tutte le cartelle genitori rispetto a 'fakeroot', se non esistenti
mkdir -p ${CONTAINER_ROOT_FOLDER}/fakeroot
cd ${CONTAINER_ROOT_FOLDER}
# Ottenimento di AlpineLinux ed estrazione archivio tarball
chown container-user. -R ${CONTAINER_ROOT_FOLDER}/fakerootConfigurazione sicura di un mount namespace (propagazione)
Come anticipato, alla creazione di un nuovo mount namespace, il namespace appena creato ottiene una copia dei mountpoint dell’host. Questo accade perché, di default, systemd è configurato per condividere ricorsivamente i mount point con tutti i nuovi namespace2.
La motivazione di questa propagazione by default è legata a una funzione nel kernel chiamata shared subtree, che permette a ogni mount point di avere associato il proprio tipo di propagazione. Il tipo di propagazione specifica in che modo gli eventi di mount e unmount di uno specifico mount point sono condivisi (o meno) con altri mount point, specialmente in diversi mount namespace o peer groups.
Peer group: definizione
Un peer group è definito come un un gruppi che propaga gli eventi gli uni agli altri. Gli eventi sono dei fenomeni come il mount di un volume (anche di rete) o l’unmount.
Con relazione ai mount namespace, i peer group sono spesso dei fattori decisivi per la visibilità di un mount e se vi è possibile interagirci.
Un bind mount permette la condivisione di una directory dell’host con un container, mentre isola la vista del proprio filesystem dall’host e da altri processi.
I vari stati (mount state) sono:
- shared: un mount che appartiene a un peer group. Qualsiasi cambiamento verrà propagato a tutti i membri del peer group3;
- slave: propagazione a senso unico. Il mount point master propagherà gli eventi a uno slave, ma il master non vedrà alcuna azione che gli slave effettueranno4;
- private: non riceve o inoltra eventi. Altri mount namespace non potranno accedere al mount point5;
- unbindable: uguale a private, ma non può essere oggetto di bind mount6.
È essenziale ricordare che lo stato del mount point vale per il mount point; quindi, nel caso di / e /boot diventa necessario di applicare stati separati a ciascuno dei due mountpoint. La maggioranza degli engine dei container utilizza lo stato private quando monta un volume all’interno del container.
Mountpoint, mount namespace & co.: quanta confusione!
Una cosa che può mandare in confusione quando si considerano i mount points è l’assunzione che, condividendo i mount points, possano condividersi parti intere del sistema operativo che ospita il container - file inclusi. In realtà, questo non è vero: un mount point non è altro che una cartella, all’interno del filesystem, che verrà riempita con i contenuti appropriati (processi per
/proc, file personali per/home, file di boot per/bootetc.). La copia di un mount point non implica che i contenuti, per un mount point, siano uguali per container e per host (e, infatti, sono diversi). Avere un mount point per/home, ad esempio, implica solamente che deve esserci, all’interno del filesystem, una cartella/homenel volume radice. Il contenuto, tuttavia, è diverso:/homedell’host avrà i file dell’utente, mentre/homenel container sarà una cartella con stesso nome, ma del tutto diversa, con i contenuti effettivi dell’utente del container.
Pivot root
pivot_root è una system call che sostituisce il root del filesystem corrente con un nuovo root. In particolare, si usa per cambiare il mount root nel mount namespace del processo chiamante7 ed è necessario per fornire sicurezza quando si eseguono dei container in diversi namespaces, in modo che due processi che vengono eseguiti in diversi namespace non entrino in conflitto.
Esistono alcune differenze con chroot:
chroot | pivot_root | |
|---|---|---|
| Tipo | Cambia la directory root apparente per un processo e i suoi figli. | Una syscall a livello kernel che cambia il mount del root nel mount namespace. |
| Effetto sulla tabella di mount | Non altera il root e la tabella di mount nel namespace globale. | Cambia il root mount nel mount namespace del processo. |
| Sicurezza | È facile uscire dalla jail e accedere al filesystem host. poiché il namespace root globale è inalterato. | Fornisce sicurezza avanzata sostituendo il root del filesystem, rendendo la syscall una misura di sicurezza fondamentale per eseguire container in diversi namespace. |
PID Namespaces
I PID namespace isolano lo spazio numerico dei process ID (process ID number space), in modo da avere gli stessi PID in namespace differenti.
Oltre all’isolamento, il sistema dei PID funziona in modo quasi identico a quello fuori del namespace:
- i process ID nel namespace iniziano da 1, con il primo che è il processo di init;
- qualsiasi processo con PID 1 è vitale per la vita del namespace;
- se il PID 1 è terminato per qualsiasi ragione, il kernel invia
SIGKILLagli altri processi nel namespace, spegnendolo a tutti gli effetti.
I PID namespace permettono ai container di fornire funzionalità come la sospensione e la ripresa di insiemi di processi nel container e la migrazione del container in un nuovo host mentre i processi nel container mantengono gli stessi PID.
Il kernel ha spazio per 32 PID namespace PID innestati. In particolare, si segue una relazione a senso unico: il genitore può vedere i PID dei figli, nipoti etc, ma non può vedere i PID dei suoi genitori.
Strumenti come ps sono namespace-aware e leggono dalla directory /proc: questo è possibile grazie al fatto che i PID namespace eredita i mount dal mnt namespace.
Per verificare che i processi sono in diversi namespace, si deve provare il PID del processo bash. Avendo eseguito l’unshare, il processo bash è il processo di init del nuovo namespace ed è il PID che sarà collegato all’ID del namespace. Usando lnsn si possono vedere i namespace e i PID.
UTS namespace
UTS namespace controlla l’hostname e il dominio NIS (Network Information Service), e non bisogna confondersi con Unix Timesharing System.
Questi identificativi sono impostati usando sethostname e setdomainname e possono essere recuperati usando uname, gethostname e getdomainname. Rende possibile avere più hostname.
net namespace
Ogni network namespace contiene le proprie proprietà delle risorse di rete in /proc/net. Ciascuno contiene solamente un’interfaccia di loopback alla creazione, mentre ogni interfaccia di rete (fisica o virtuale) sarà presente solamente una volta per namespace.
È possibile che un’interfaccia sia spostata tra diversi namespace.
Ogni namespace contiene un insieme privato di indirizzi IP, la propria routing table, l’elenco delle socket, la connection tracking table, firewall e altre risorse di rete.
Cgroup (Control groups)
I Cgroup sono una risorsa integrata nel kernel che permette all’amministratore di impostare limiti di utilizzo su ogni processo del sistema, tra cui:
- il numero di CPU shares (condivisioni di CPU) per processo;
- il limite sulla memoria per processo;
- limiti di I/O per dispositivi a blocchi (block device I/O) per processo;
- quali pacchetti di rete sono identificati come dello stesso tipo in modo che un’altra applicazione possa imporre regole sul traffico di rete.
I cgroup hanno quattro funzioni strettamente collegate che li rendono importanti sui sistemi moderni, specialmente quando si eseguono carichi di lavoro in container:
- resource limiting: permettono a un amministratore di assicurare che programmi in esecuzione sul sistema rimangano in certi limiti accettabili per CPU, RAM, block device I/O e device groups;
- prioritization: permette di specificare, a prescindere da quante risorse sono disponibili, che il processo
Xabbia sempre più tempo sul sistema del processoY; - accounting: permette di monitorare l’utilizzo delle risorse, ma è spento di default sulla maggior parte delle distro Linux enterprise a causa del maggiore consumo di risorse;
- process control: la possibilità di fare snapshot di un processo in particolare e dispostarlo (anche noto come freezer).
Cgroups - Version 1
I croups sono dei meccanismi per controllare determinati sottosistemi nel kernel, detti controller. Ogni tipo di controller è diviso a sua volta in strutture ad albero, in cui ogni ramo o foglia ha i suoi pesi e limiti. Un cgroup ha più processi associati, rendendo l’utilizzo di risorse granulare e il fine tuning facile.
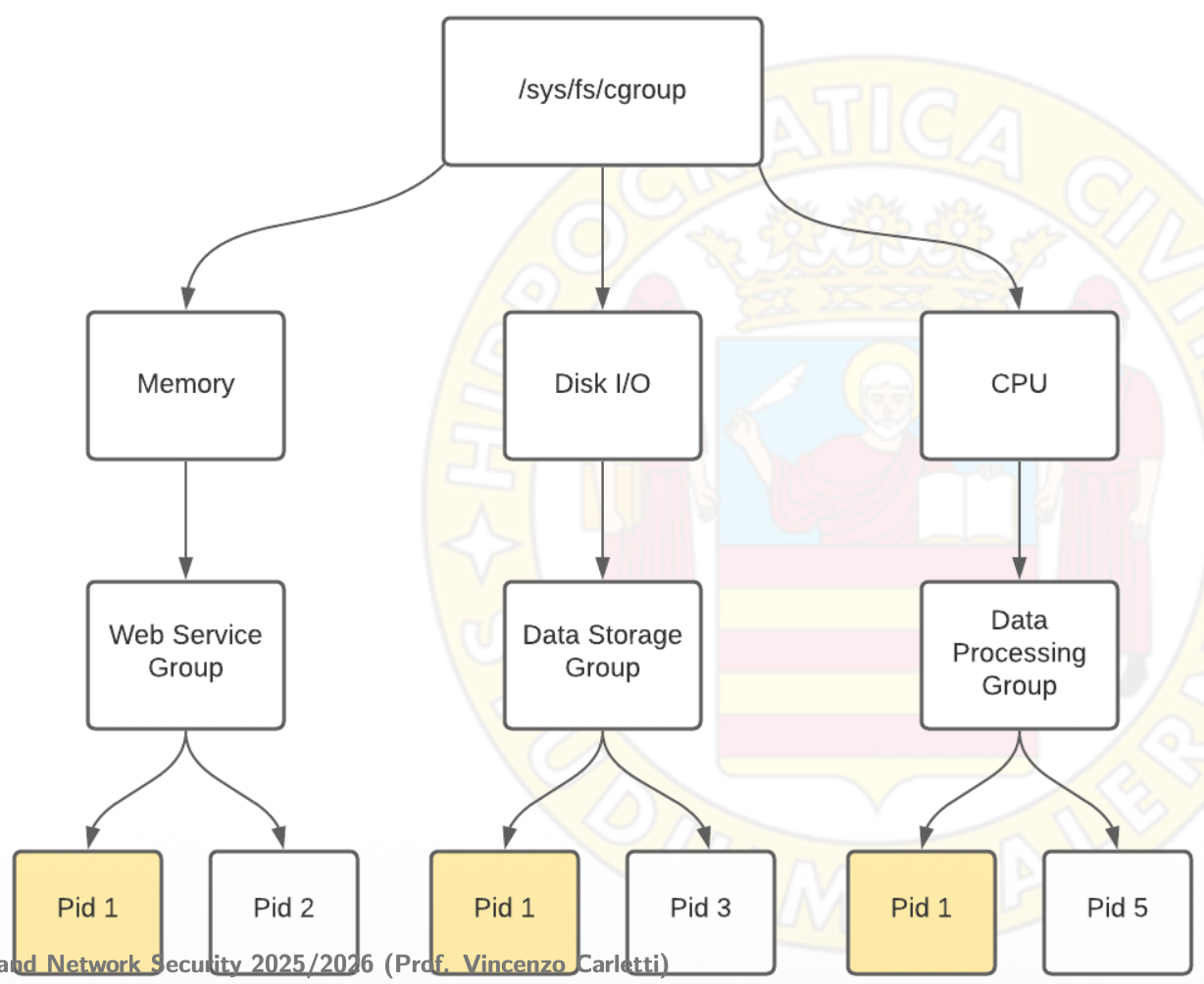
systemd-nspawn (“chroot on steroids”)
systemd-nspawn è una utility che permette a un amministratore di creare un comando o un intero OS in un container leggero. È incluso nella suite systemd ed è usato per eseguire container di sistema leggeri in Linux.
Differenza tra systemd-nspawn, Docker e LXC
- Isolation level:
systemd-nspawnoffre isolazione per il filesystem, la rete e i processi, ma è privo di un’integrazione profonda con le funzioni del kernel come LXC e Docker. Docker, fornisce un isolamento più avanzato con strumenti come i cgroups per la gestione delle risorse; - simplicity:
systemd-nspawnè più trasparente per utenti familiari con l’ecosistemasystemde non richiede strumenti aggiuntivi per la gestione dei container, rendendolo ideale per piccoli progetti o per chi cerca semplicità; - use case: mentre Docker è pensato per le applicazioni in container,
systemd-nspawnè più adatto per eseguire interi sistemi operativi, specialmente per scenari di test o di sviluppo; - integration with
systemd: essendo parte disystemd,systemd-nspawnsi integra seamlessly con i servizi disystemd, rendendo facile la gestione di container come servizi del sistema operativo.
Esempio di uso di systemd-nspawn con Deboostrap:
sudo apt install deboostrap systemd-container
sudo mkdir -p /var/lib/containers
# Preparing the OS mount
sudo debootstrap trixie /var/lib/containers/deb-trixie
# l'opzione -D viene usata per speciicare la root directory del container
# si lancerà un singolo comando all'interno del container
sudo systemd-nspawn -D /var/lib/containers/deb-trixie
# passwd lanciato nel container
passwd
# opzione -b per cercare un processo di init valido ed eseguirlo, così da avere il lancio del sistema (full boot sequence)
sudo systemd-nspawn -b -D /var/lib/containers/deb-trixieFootnotes
-
L’opzione
.specifica il gruppo (primary group) da assegnare all’utente, che equivale a:chown container-user:container-userL’opzione
-R, invece, specifica che il comando deve essere applicato ricorsivamente (quindi anche tutti i file e le sottocartelle infakerootsaranno oggetti del cambio di proprietà). ↩ -
Se, tuttavia, si montasse un nuovo filesystem nel nuovo mount namespace, questo non sarebbe visibile nel mount namespace dell’host. ↩
-
Scenario di esempio: il container monta un filesystem temporaneo su
/data/temp. Il container vede il mountpoint, l’host no. ↩ -
Scenario di esempio: l’host monta un nuovo drive USB su
/data/USB. L’host vede il nuovo mountpoint, il container no. ↩ -
Scenario di esempio: l’host prova un bind mount di
/datasu/mnt/dataall’interno del container. Il mount fallisce. ↩ -
pivot_rootdeve essere effettuata dal processo chiamante, cioè dal container. In verità, questa system call viene effettuata dal processo che diventerà il processo iniziale del container (runtime process). ↩