è trasparente (consente di vedere e manipolare tutte le sue componenti);
offre un controllo granulare;
la maggior parte dei tool per l’hacking sono scritti per Linux.
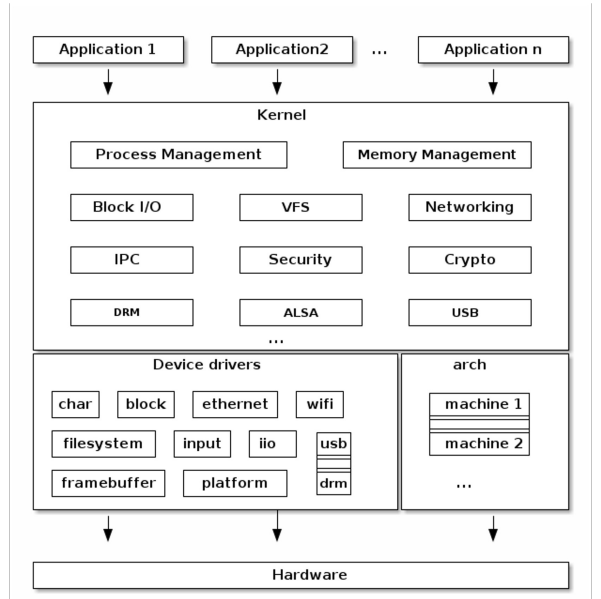
Architettura di un sistema Linux
Implementazione delle syscalls
Vi è uno strato software che è un’interfaccia per il kernel, detta chiamate di sistema^[Win32API per Windows, POSIX API per gli Unix-Like, Java API per la JVM. ]. Le librerie per le funzioni più comuni sono scritte sulla base delle chiamate di sistema, ma un applicativo può scegliere di usare entrambe (pur essendo raro). Il vantaggio di avere un programma scritto sfruttando le API, anziché le chiamate di sistema, è di avere un software che è portabile su quasi ogni OS.
L’implementazione delle chiamate di sistema prevede che, per ogni system call, vi sia associato un numero, memorizzato in una tabella indicizzata dall’interfaccia delle chiamate di sistema. Questa poi invoca la chiamata desiderata nel kernel dell’OS e ritorna sia lo stato della syscall, che eventuali valori di ritorno.
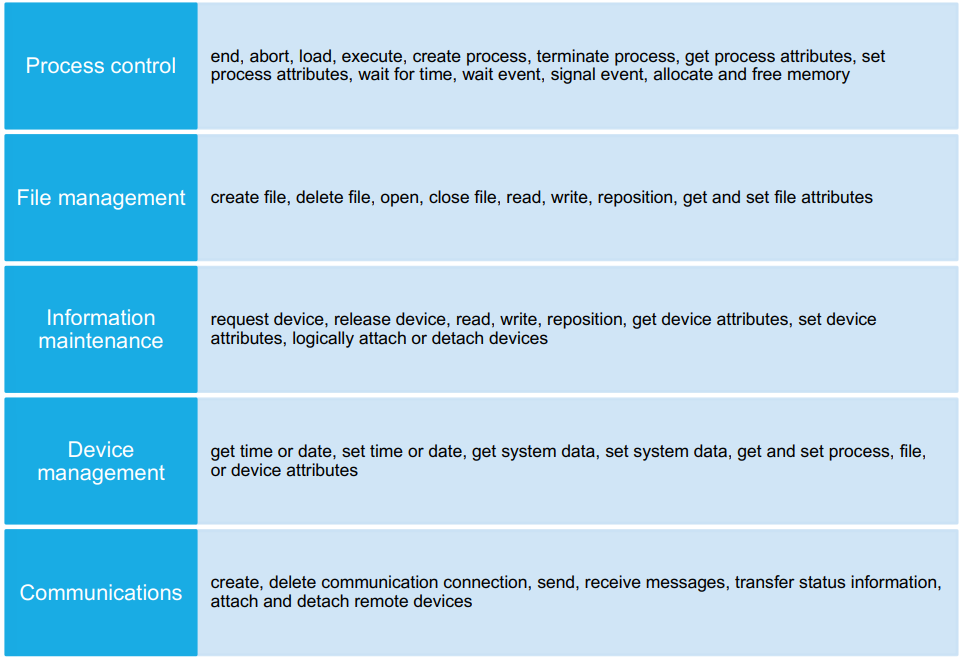
I diversi tipi di syscall:
File descriptors
Nei sistemi Unix-Like, a ciascuna sorgente di input o output viene associato un identificativo unico, detto file descriptor, che fa parte della POSIX API. Ogni volta che viene aperto o creato un nuovo file, infatti, il kernel ritorna un file descriptor, che è rappresentato da un numero intero, non negativo, che verrà usato per riferirsi al file nelle syscall seguenti.
I descriptors standard sono forniti a ciascun processo di default e risultano essere:
standard input (0),
standard output (1),
standard error (2).
Shell
Si distinguono diverse categorie di shell:
shell interattiva: una shell che riceve comandi da un utente e ne mostra l’output;
shell non interattiva: una sottoshell probabilmente eseguita da un processo automatico.
Ma anche:
login shell: una shell che svolge la funzione di login, per la quale è necessario username e password;
non login shell: una shell che viene eseguita senza login.
Relazione genitore-figlio nelle shell
La shell interattiva di default avviata quando si esegue un emulatore di terminale è la shell genitore; la sua funzione è quella fornire un prompt da riga di comando in cui è possibile inserire un comando, per restituirne l’output.
Quando si esegue:
/bin/bash
oppure un comando equivalente per lanciare una nuova shell, si avvia un’altra shell che verrà detta shell figlia, che ha le stesse funzioni della shell genitore. Dalla shell figlia è possibile avviare un’ulteriore subshell.
All’avvio di un processo shell figlio, solo parte dell’ambiente della shell genitore è copiato nell’ambiente della shell figlia.
La chiusura della shell genitore comporta la chiusura anche delle shell figlie^[Graceful closure: la shell viene chiusa in modo sicuro, svolgendo compiti come salvataggio dati, rilascio delle risorse e registrazione degli eventi.].
Lista di processi
Si può avviare una lista di processi elencando diversi comandi sulla stessa riga, separando ciascun comando con un ’;’ e racchiudendo tutto tra parentesi^[Qualora non vi fossero le parentesi, i comandi sarebbero eseguiti uno dopo l’altro senza la creazione di una subshell.]. Questo comporta la creazione di una nuova subshell, in cui sono eseguiti tutti i comandi.
Una lista di processi è un comando di raggruppamento.
Per controllare se si è in una subshell, è possibile visualizzare:
echo $BASH_SUBSHELL
che ritorna:
0 se non vi sono subshell;
1 o più se vi sono una o più subshell.
Utilizzare una sottoshell, tuttavia, è un’operazione esosa e può rallentare anche significativamente il processamento dei dati.
Background mode
È possibile lanciare anche un comando in background, aggiungendo una & dopo il comando. È possibile anche avere processamento in una shell, senza essere vincolati ad eventuali I/O di una subshell.
È possibile anche avere co-processing, con il comando:
coproc [command]
che comporta la creazione di una subshell in cui viene eseguito il comando in background.
È possibile definire un processo con la sintassi estesa:
coproc My_job { sleep 10; }
Redirezione dell’I/O
Si tratta di una funzione della shell in grado di reindirizzare l’output e l’input su e da file; visto che stdin, stdout e stderr sono gestiti come file ordinari, la redirezione funziona anche con questi flussi.
Esistono due operatori:
>: ridirige l’output dell’operando sinistro in input all’operando destro, creando il file se non esiste, o sovrascrivendolo
>>: effettua la redirezione in modo uguale a >, procedendo con append se il file di output esiste già.
Si può redirigere a stdout o stderr con l’operatore &1.
Piping
L’operatore pipe | ridirige l’output di un processo, espresso come operando sinistro, come input di un altro processo, espresso come operando destro.
Comandi built-in
Dalla shell è possibile avviare anche comandi esterni, che esistono cioè al di fuori della shell. Ogni volta che uno di questi comandi è richiesto, viene creato un nuovo processo figlio (fork): questo può rendere l’esecuzione di un comando esterno un’operazione esosa.
Viceversa, un comando built-in non ha necessità di creare un processo figlio. Questi comandi sono compilati nella shell e ne sono parte.
Variabili d’ambiente
La shell usa le variabili d’ambiente per conservare delle informazioni riguardo la sessione e l’ambiente di lavoro. Si distinguono due tipi di variabili:
variabili globali, visibili fuori dalla sessione e da ogni subshell figlia;
variabili locali, visibili solo dalla shell che la crea.
È possibile creare una variabile globale creandola dapprima nell’ambiente locale, e poi facendone l’export:
my_variable="Global"export my_variable
Cambiare una variabile globale in una shell figlia non comporta il cambiamento del valore della variabile in una shell genitore.
È possibile rimuovere una variabile esistente col comando unset; nelle shell figlie, il cambiamento si applica solo alle shell figlie.
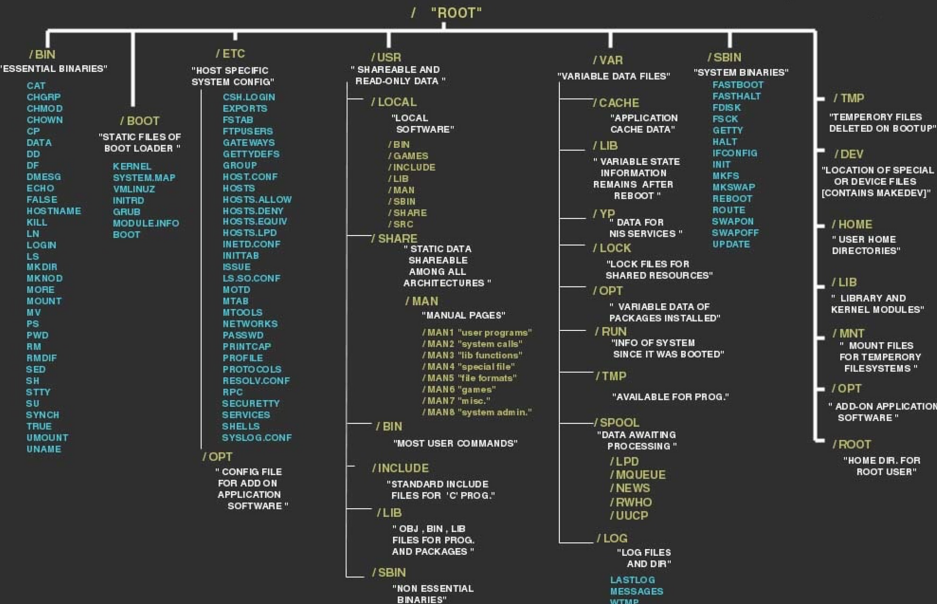
Filesystem
Nel filesystem Linux, tutto è visto come un file. I file sono detti regular files. Esistono inoltre:
directories (d), cioè files che sono liste di altri file;
special files (c), meccanismi per input e output (per la maggior parte in /dev);
link (l), un sistema per fare in modo che un file o una directory sia visivile in più parti del tree del filesystem;
socket (s), che consentono la comunicazione di rete inter-processo e protette dal meccanismo del sistema di controllo degli accessi;
named pipes (p), che sono simili alle socket e rappresentano un modo per far comunicare più processi, senza usare la semantica delle socket di rete;
block devices (b), un dispositivo di storage che sposta dati in sequenze di bytes o bit (blocchi).
Mounting
L’operazione di mounting è necessaria quando si vuole collegare un nuovo dispositivo di storage, visto che i sistemi Unix hanno solo una directory root. Al contrario, l’unmounting è l’operazione duale e serve principalmente per risolvere problemi di sincronizzazione.
/etc/fstab
In Linux è presente il file fstab (sotto /etc/fstab), un file di configurazione che contiene informazioni sui vari filesystem noti al sistema e su come questi debbano essere montati ed usati, ciascuno per riga. Ogni riga possiede 6 attributi:
block device, che specifica il block device o la partizione che contiene il filesystem (identificabile mediante l’UUID, una label o i nomi tradizionali come /dev/sdxy);
mount point, la directory in cui verrà montato il filesystem;
tipo, specifica il tipo di filesystem da montare;
options, una lista di opzioni di mount associate al filesystem;
dump, specifica se il filesystem deve essere considerato nei backup (1) o ignorato (0);
pass, determina l’ordine in cui vengono svolti i check sul filesystem (0 disabilita il check, 1 se deve essere controllato prima come nel caso del filesystem root, 2 se il filesystem deve essere controllato dopo il filesystem root).
Le opzioni del punto 4 sono:
ro: mount in sola lettura;
rw: mount in lettura e scrittura;
sync/async: controlla come sono svolte le operazioni di input e output. In particolare, con async le operazioni sono svolte in maniera asincrona per migliore prestazioni, mentre con sync i dati sono scritti in modo sincroni e, cioè, immediatamente;
noexec: impedisce l’esecuzione di binari nel filesystem^[Dalla risposta di ChatGPT, si evidenzia solo un limite che viene posto agli attacchi di privilege escalation su /tmp.];
nosuid: blocca le operazioni di setuid e setgid sui bit del filesystem (si prevengono gli attacchi di tipo privilege escalation mediante binari);
auto/noauto: consente automaticamente al filesystem di essere montato all’avvio oppure quando viene lanciato il comando di mount, mentre noauto specifica che il filesystem deve essere montato esplicitamente;
user/nouser: consente a qualsiasi utente di montare il filesystem, implicando noexec, nosuid, nodev se non sovrascritti, mentre nouser è l’opzione di default e consente il mount solo all’utente root;
relatime/noatime: relatime aggiorna l’ora di accesso del file e delle directory sono se sono modificate o se l’ultimo accesso è meno recente della modifica corrente, mentre noatime migliora le prestazioni a scapito della perdita di questa informazioni;
uid=, gid=: consentono di specificare l’ID utente e l’ID del gruppo che possiederanno i file del filesystem^[Particolaermente utile per vfat o ntfs che non supportano i permessi di Linux.].
Con defaults, si imposta: rw, suid, dev, exec, auto, nouser, async.
Linux LVM (Logical Volume Management)
Si tratta di un metodo di gestione dello storage diverso rispetto al tradizionale basato su partizioni. Infatti, invece di creare partizioni, si possono creare dei volumi logici da poter montare come se fossero delle partizioni.
I tre componenti principali di LVM sono:
volumi fisica;
gruppi di volumi;
volumi logici.
I componenti vengono poi amministrati da un modulo a livello kernel, detto device mapper.
Il vantaggio principale di questa soluzione è la semplicità del resize di volumi logici o gruppi di volumi.
Utilizzando LUKS, inoltre, è possibile crittografare i volumi.
Utenti, gruppi e controllo degli accessi
Utente: definizione
In Linux, è utente è un’entità che può manipolare dei file e fare altre operazioni.
Gli utenti sono divisi in due categorie, sulla base del loro livello di accesso:
superutente (anche root o amministratore): può accedere a tutti i file sul sistema;
utente normale: accesso limitato.
A ciascun utente è assegnato un ID unico in tutto il sistema operativo. In particolare:
0 è assegnato all’utente root;
1-999 agli utenti di sistema^[Sono usati da demoni e altri servizi di sistema.];
1000+ assegnati agli utenti locali^[Quelli che effettivamente usano la macchina.].
La creazione di un utente prevede le seguenti fasi:
assegnazione dell’UID all’utente;
creazione di una home directory;
impostazione della shell di default;
creazione di un gruppo privato di utenti, chiamato come lo username dell’utente;
i contenuti di /etc/skel sono copiati nella home directory del nuovo utente;
copia dei file .bashrc e similari nella home directory del nuovo utente.
Gruppi
Un gruppo è una collezione di utenti, il cui scopo principale è quello di stabilire un insieme di permessi per una certa risorsa che possano essere condivisi da utenti nello stesso gruppo.
Esistono due tipologie di gruppi:
gruppo primario, che è quello assegnato ai file creati dall’utente^[Di default, corrisponde a quello nominato allo stesso modo dell’utente. Ogni utente deve necessariamente appartenere ad un gruppo.];
gruppo secondario (o supplementare), che sono usati per dare un certo insieme di permessi a degli utenti.
Autenticazione dell’utente
L’autenticazione di un utente rappresenta il primo blocco fondamentale per la creazione di un sistema di difesa e rappresenta perciò la base per la maggioranza dei sistemi di controllo degli accessi.
Autenticazione: definizione (RFC 4949)
L’autenticazione è il processo di verifica di un’entità dichiarata da un’entità.
Questo processo segue due fasi:
identificazione, che consiste nel presentare un identificativo ad un sistema di sicurezza;
verifica, che consiste nel presentare o nella generazione di informazioni di autenticazioni in grado si sostenere un’associazione tra l’entità e l’identificativo.
Mezzi di autenticazione possono essere:
ciò che un individuo conosce;
ciò che un individuo possiede;
ciò che un individuo è (static biometrics);
ciò che un individuo fa (dynamic biometrics).
Autenticazione in Linux
L’autenticazione in Linux segue 3 fasi:
processo di login, in cui un utente prova ad accedere in un sistema Linux, con il sistema che chiede all’utente di inserire username e password;
username validation, in cui il sistema controlla che esiste lo username (nel file /etc/passwd);
verifica della password, con cui si verifica la correttezza della password, se esiste l’utente. Le password non sono salvate in plain text ma in forma di hash nel file /etc/shadow.
/etc/passwd
Il file /etc/passwd contiene le informazioni sugli utenti del sistema. Ogni riga è costituita da:
username;
password (se valorizzato con x significa che una password crittografata è salvata nel file /etc/shadow);
lo user ID (UID);
l’ID del gruppo dell’utente (GID);
informazioni aggiuntive come il nome completo dell’utente (GECOS);
il path assoluto della home directory di quell’utente;
la shell di login dell’utente.
Il formato è: [username]:[password]:[UID]:[GUD]:[GECOS]:[home_dir]:[shell_path].
/etc/shadow
Contiene le password in forma di hash degli utenti, modificabili col comando:
passwd
Ogni riga di questo file contiene i seguenti field:
username;
password, in forma di hash. In particolare, possono verificarsi altre situazioni per cui vi sono:
una blank entry, che vuol dire che non è necessaria una password per loggarsi all’account;
un asterisco, che indica che l’account è stato disabilitato.
l’epoch dell’ultimo cambio password;
il numero minimo di giorni dopo i quali l’utente può cambiare la propria password;
password validity, il numero di giorni dopo i quali la password scadrà;
warning period, cioè il numero di giorni prima la data della scadenza, in cui l’utente riceverà avvisi e notifiche per effettuare una modifica della password;
account validity, cioè il numero di giorni dopo cui l’account verrà disattivato una volta scaduta la password;
account disability, indica il numero di giorni in cui l’utenza è stata disabilitata (Unix Epoch).
Il formato è: [username]:[password]:[last_pwd_change]:[pwd_validity]:[warn_date]:[acc_validity]:[acc_disability].
Altri metodi di autenticazione
Esistono altre modalità di autenticazione, come:
PAM (Pluggable Authentication Modules), cioè un metodo flessibile per configurare schemi di autenticazione (ad esempio, con l’autenticazione a due fattori o con la biometria);
chiavi SSH, da utilizzarsi per autenticarsi al posto della password per autenticarsi alle secure shell^[L’accesso mediante chiave SSH prevede la creazione di una coppia di chiavi crittografiche: una privata, tenuta segreta, e una pubblica, conservata sul server in ~/.ssh/autorized_keys.];
Kerberos, un protocollo di autenticazione pensato per un’autenticazione sicura su reti non sicure, mediante un sistema di ticket in sostituzione alle password.
Controllo degli accessi
Controllo degli accessi: definizione (RFC4949).
Il controllo degli accessi è un insieme di misure che implementano e garantiscono servizi di sicurezza in un sistema informatico, in modo particolare quelle che forniscono il servizio di controllo degli accessi, specificando chi o cosa possono avere accesso a ciascuna risorsa del sistema e il tipo di accesso che è permesso ad ogni isntanza.
Il controllo degli accessi ha diverse componenti fondamentali:
autenticazione, che è la verifica di validità delle credenziali fornite;
autorizzazione, la fase con cui si concedono i permessi ad un’entità di accedere ad una certa risorsa;
audit, una verifica indipendente e l’analisi dei record di sistema e delle attività, per testare l’adeguatezza dei controlli di sistema, per garantire compliance con le policy stabilite e le procedure operative, per rilevare fughe di sicurezza e per suggerire qualsiasi cambiamento nei controlli, policy e procedure.
Policy per il controllo degli accessi
Discretionary access control (DAC): controlli basati sull’identità del richiedente e su regole di accesso (autorizzazioni) che descrivono quali richiedenti possono fare che cosa. Questa policy può permettere ad un’entità di garantire l’accesso alla stessa risorsa ad un’altra entità;
mandatory access control (MAC): il controllo degli accessi è basato sul confronto di etichette di sicurezza (che indicano quanto critica è una risorsa) con le autorizzazioni di sicurezza (che indicano quali entità del sistema sono autorizzate ad accedere a quali risorse). Questa policy non permette ad un’entità di garantire l’accesso alla stessa risorsa ad un’altra entità;
role-based access control (RBAC): il controllo degli accessi è basato su dei ruoli che l’utente deve avere all’interno del sistema che specificano cosa è permesso ad un utente in un determinato ruolo;
attribute-based access control (ABAC): il controllo degli accessi si basa su attributi dell’utente, la risorsa cui si deve accedere e le condizioni dell’ambiente.
Si distingue tra:
soggetto, che è l’entità in grado di accedere agli oggetti ed è uguagliabile ad un processo;
oggetto, che è la risorsa il cui accesso è controllato.
Forme di base del controllo degli accessi individuano tre classi di soggetti:
owner (proprietario), che può essere il creatore della risorsa (come un file);
group (gruppo), in aggiunta ai privilegi assegnati al proprietario, ad un certo gruppo di utenti possono essere permessi i diritti di accesso;
world, cioè utenti che possono accedere al sistema ma non sono inclusi nelle categorie gruppo e proprietario per la risorsa, con il minor numero di permessi.
Inoltre, i permessi solitamente disponibili sono:
read, per la sola visione di informazioni di una risorsa;
write, per l’aggiunta, modifica o eliminazione di dati in una risorsa ed implica l’accesso in lettura;
execute, per l’esecuzione di determinati programmi;
delete, per l’eliminazione di determinate risorse;
create, per la creazione di nuovi dati;
search, per elencare i file in una directory o cercare in una directory.
Controllo degli accessi ai file in Unix
Il sistema per il controllo dell’accesso ai file nei sistemi Unix segue quanto appena descritto.
Ad ogni file, sono associati 12 bit di protezione. Questi bit, insieme all’ID del proprietario e del gruppo, fanno parte dell’inode del file. 9 dei bit di protezione specificano i permessi di lettura, scrittura ed esecuzione del proprietario del file, del gruppo cui quel file appartiene e tutti gli altri utenti. Se applicato ad una directory, i bit per i permessi di lettura e scrittura indicano, rispettivamente, il permesso di elencare e modificare le informazioni dei file della directory, mentre il bit per il permesso di esecuzione descrive il permesso di cercare un file nella directory.
I rimanenti 3 bit specificano comportamenti aggiuntivi di file e directory; due di questi sono i permessi per impostare l’UID (SetUID) e il GID (SetGID). Se questi sono impostati su un file eseguibile, il sistema operativo opererà allocando i permessi del proprietario del file all’utente che esegue il file^[Si parlerà di effective user ID.], per consentire la creazione e l’uso di programmi che richiedono certi permessi per usare file altrimenti non accessibili; quando applicato ad una directory, SetUID viene ignorato, mentre SetGID indica che i nuovi file erediteranno il gruppo specificato dalla directory.
L’ultimo bit indica il permesso di sticky^[Non più usato.], che indica che il sistema debba mantenere il contenuto del file in memoria dopo la sua esecuzione; quando applicato ad una directory, specifica che solo il proprietario di ciascun file nella directory può rimuovere, spostare o rinominare il file.
DAC in Linux
Il Discretionary Access Control in Linux viene realizzato con chown e chmod, che consentono di evitare le implicazioni contro la sicurezza che si avrebbero avendo i bit SUID e SGID su file che non ne avrebbero bisogno.
Access control list
L’approccio appena descritto è comunemente noto come lista di controllo accessi minimale (Minimal ACL). Molti sistemi Unix moderni supportano anche l’approccio esteso.
Questa strategia prevede di lasciare inalterato il significato dei primi 9 bit. I permessi del proprietario e del gruppo proprietario rappresentano i massimi permessi che possono essere concessi agli utenti o ai gruppi, diversi da quelli del proprietario: in questo caso, il gruppo rappresenta una maschera. Altri utenti e gruppi possono essere associati al file, ciascuno con un campo da 3 bit per specificare i permessi: i permessi elencati sono comparati con il campo maschera rappresentato dal gruppo e, ogni permesso non presente nella maschera, è disabilitato.
Quando si richiede accesso ad un oggetto del filesystem, si seguono due step:
selezione dell’entry nell’ACL che più si avvicina al processo che richiede la risorsa (si confronta, in ordine: proprietario, utenti, gruppi, altri) e solo una singola entry determinerà l’accesso;
controlla se l’entry corrispondente contiene sufficienti permessi. Considerando che ciascun processo può essere membro in più gruppi, più di una entry relativa ai gruppi può corrispondere; in particolare:
se una di queste entry relative ai gruppi contiene i permessi richiesti, se ne sceglie una e il risultato è uguale a prescindere dalla entry scelta;
se nessuna entry contiene i permessi, l’accesso sarà negato a prescindere dalla entry scelta.
In più, si può fare uso anche degli attributi estesi dei file, che possono proteggere file sensibili dall’eliminazione o modifica.
sudoers
Il file sudoers è un file di configurazione del comando sudo che consente di specificare quali utenti hanno il permesso di eseguire quali comandi e se possono usare i privilegi elevati.
La struttura di ogni riga del file è la seguente: utente host = (utenti effettivi) comandi, in cui:
utente specifica l’utente o il gruppo di utenti a cui si vuole concedere permessi;
host specifica il nome dell’host su cui si applica la direttiva;
utenti effettivi specifica gli utenti sotto cui il comando sarà eseguito (as which user);
comandi l’elenco di comandi che l’utente può eseguire con permessi elevati.
Di solito, vi è un timer di 5 minuti entro i quali non sarà necessario reinserire la password per usare il comando sudo. Dal momento in cui questo può rappresentare un problema di sicurezza, è possibile aggiungere una riga nella sezione Defaults (Defaults timestamp_timeout = 0) del file sudoers per disabilitare questo comportamento, richiedendo la password ogni volta che si lancia il comando sudo.
Gestione dei processi
Processo: definizione
Con processo si intende un’istanza di un programma, in esecuzione.
Ogni processo fornisce al programma due astrazioni chiave:
il controllo logico del flusso, grazie al quale ogni programma crede di avere uso esclusivo della CPU;
spazio degli indirizzi (di memoria) privato e virtuale, con cui il programma crede di avere uso esclusivo della memoria centrale.
Questo viene mantenuto con l’intervallamento dell’esecuzione dei processi (cioè il multitasking) e lo spazio di indirizzamento della memoria è gestito dal sistema della memoria virtuale.
Ogni processo viene rappresentato nel sistema operativo con una struttura dati detta Process Control Block (PCB). Una tavola dei processi viene usata per mantenere informazioni dei processi nel sistema (/sys/proc).
Un processo può trovarsi in uno dei seguenti stati:
R, Running o Runnable. Quando un processo è avviato, viene messo in stato runnable o running (eseguibile o in esecuzione) e, quando è in stato running, il processo è eseguito su uno dei core della CPU;
D, uninterruptible sleep. Quando un processo si trova in questo stato, il processo aspetta che delle risorse diventino disponibili prima di passare in stato runnable, non reagendo a nessun segnale;
S, interruptible sleep. Il processo reagisce a segnali e alla disponibilità di una risorsa desiderata;
T, stopped. Si passa in questo stato dallo stato runnable o running. Il processo può poi essere rimesso in stato runnable o running;
Z, zombie. Si ha un processo in questo stato quando invia il segnale SIGCHLD al processo padre e vi permane finché il processo padre non lo cancellerà dalla tavola dei processi.
Con segnale si intende un evento generato dal sistema in risposta ad una certa condizione al quale un processo può prendere delle azioni e possono essere generati dal sistema o dall’utente.
Esistono 5 classi di segnali:
process control;
resource control;
I/O notification;
hardware condition;
software condition.
Gestione dei servizi
Demoni: definizione
Con demone si intende un programma con un unico scopo, eseguito in background. In Windows, l’equivalente è un servizio.
init
init è il processo padre di tutti i processi e viene eseguito al boot del sistema. Il suo compito principale è quello di creare processi a partire dagli script contenuti in /etc/inittab e avvia tutti i processi in background dopo aver impostato il runlevel di default del sistema operativo, cioè una configurazione software del sistema che permette solo a certi gruppi di processi di esistere.
systemd
systemd è un gestore di servizi per i sistemi operativi Linux che ha sostituito initd. Quando viene eseguito come primo processo al boot, svolge le stesse funzioni di init.
È bene notare che diverse istanze di systemd sono usate al login degli utenti per avviare i propri servizi; infatti:
se eseguito come istanza di sistema, systemd userà il file di configurazione system.conf e i file in syestem.conf.d;
se eseguito come istanza d’utente, systemd userà il file di configurazione user.conf e i file in user.conf.d.
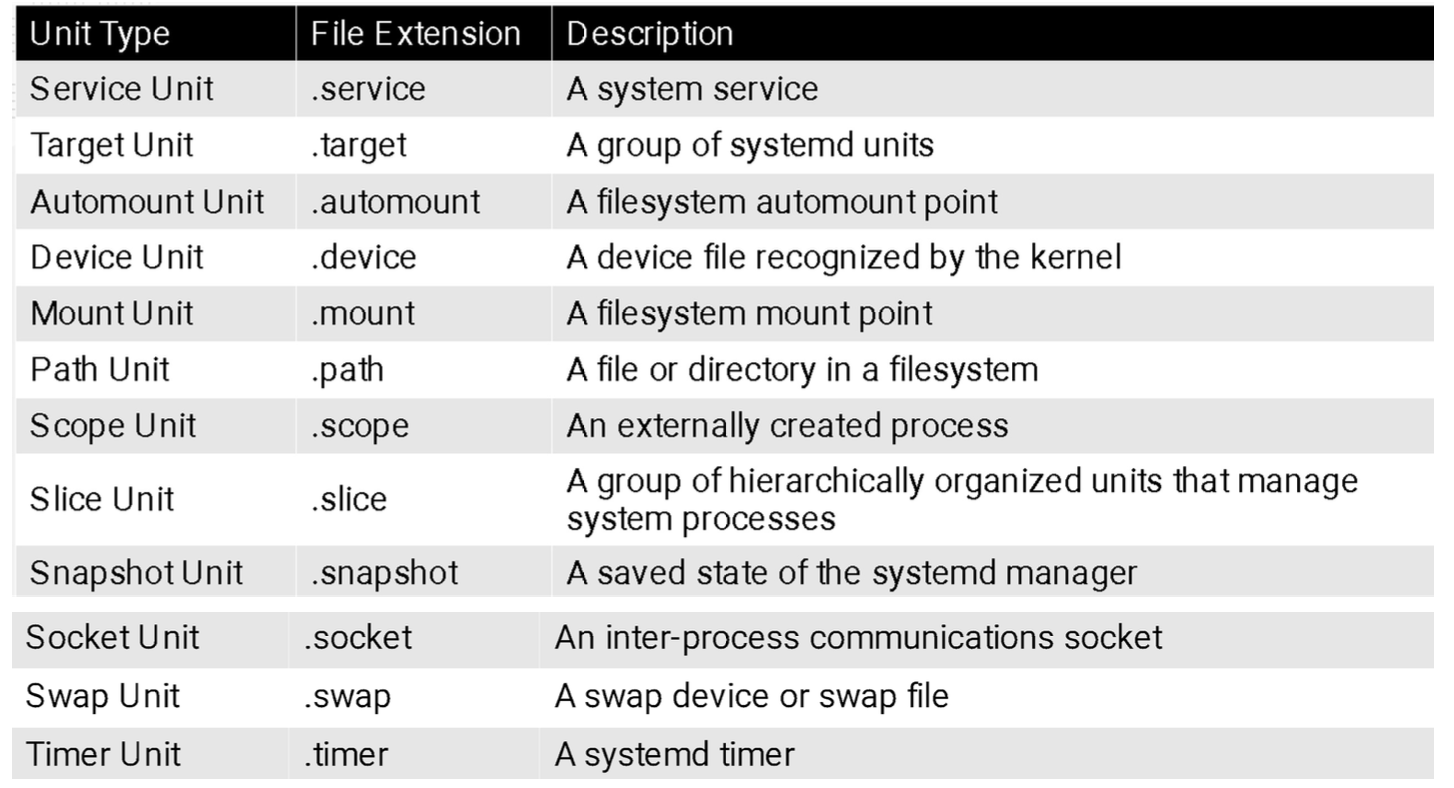
Gli script di init vengono sostituite con delle service unit, cioè degli oggetti usati per organizzare i task da svolgere in fase di boot e in fase di manutenzione. Ciascuna unit ha un nome e un tipo e, la configurazione di ciascuna, avviene mediante un file, salvato in /etc/systemd/system.
I diversi tipi di unit sono:
Ciascuna unit è organizzata in sezioni:
unit, con delle opzioni generiche;
type, direttive specifiche per quel tipo di unit;
install, informazioni per abilitare e disabilitare la unit.
Inoltre, i runlevel sono sostituiti da unità di tipo target.
Si può usare crontab per schedulare l’esecuzione di jobs.
Gestione di rete
Un host Unix può avere associato un hostname, cioè il nome di quell’host. Gli hostname possono essere risolti non solo con l’uso di DNS, ma anche mappando localmente gli host al loro indirizzo nel file /etc/host.
Il comando di base più usato per controllare la configurazione delle interfacce di rete è ifconfig. Sebbene il più del setup possa essere fatto mediante il di configurazione /etc/network/interfaces, spesso si usano dei tool come netplan.
netstat è invece un tool utile per controllare l’attività di rete.
ip può essere utilizzato per vedere e manipolare la tabella di routing. Questa contiene diversi campi:
destination, la rete o l’host di destinazione;
gateway, l’indirizzo IP del prossimo hop router usatoper raggiungere la destinazione;
genmask, la maschera di rete per la rete di destinazione, usando la notazione CIDR;
flags, una lista di flag che descrivono la entry (ad esempio, se la route è attiva o se usa il gateway);
metric, una metrica che determina il miglior percorso per la destinazione (più basso è meglio) e può essere usata per dare priorità a determinate rotte anziché altre;
ref, il numero di referenze alla entry;
use, il numero di pacchetti che sono stati inviati usando la entry;
iface, il nome dell’interfaccia di rete usata per mandare pacchetti al prossimo hop.
Per rendere persistenti le routes, è necessario salvarle nel file /etc/sysconfig/network-scripts/route-<interface>. In alternativa, si può usare NetworkManager oppure systemd-networkd.
Su Linux è possibile anche osservare la tabella ARP ed, eventualmente, modificarla. Questo è possibile col comando arp e, solitamente, si utilizza per eliminare indirizzi duplicati che possono causare problemi ad intermittenza.
Esiste un tool che si usa per effettuare la ricognizione di una rete LAN, inviando richieste ARP: netdiscover. Può essere usato:
attivamente, per scansionare un determinato range di IP;
passivamente, usando le richieste ARP e intercettando il traffico ARP per rilevare dispositivi.
Audit
In Linux vi è un demone che può essere sfruttato per svolgere audit: auditd. Questo componente può essere utilizzato per monitorare degli oggetti, secondo delle regoleˆ[Queste non sono persistenti al riavvio. Per fare in modo che lo siano, occorre modificare il file /etc/audit/audit.rules specificandovi la regola da rendere persistente.].
I log vengono generati in /var/log/audit/audit.log. Sebbene questo sia un file plain text, non è solitamente utilizzato as it is, ma viene dato in pasto ad utility quali ausearch e aureport che si occupano di rendere più leggibile il contenuto del log.
Log di sistema
I log sui sistemi Linux sono salvati sempre nella cartella /var/log. Di default, vi sono due tipi di log:
il file di log principale (Debian: syslog, RedHat: messages);
il log di autenticazione (Debian: auth.log, RedHat: secure).
Possono esserci anche altri log, come kern.log per eventi del Kernel Linux e del Firewall, wtmp e utmp (file binari) su utenti loggati e storico degli utenti, btmp per i tentativi falliti di accesso e lastlog (file binario) che contiene informazioni sull’ultimo login dell’utente.
Formato BSD in syslog
I messaggi in syslog sono codificati con il formato BSD. Questo si compone di tre parti:
PRI, un codice che rappresenta la severità del messaggio e la facility;
header, contiene un timestamp e un’indicazione dell’hostname o dell’indirizzo IP del dispositivo;
msg, diviso in due campi:
TAG, cioè il nome del programma che ha generato il messaggio;
CONTENT, cioè il contenuto del messaggio (in forma libera come una serie di caratteri stampabili).
La lista delle facilities:
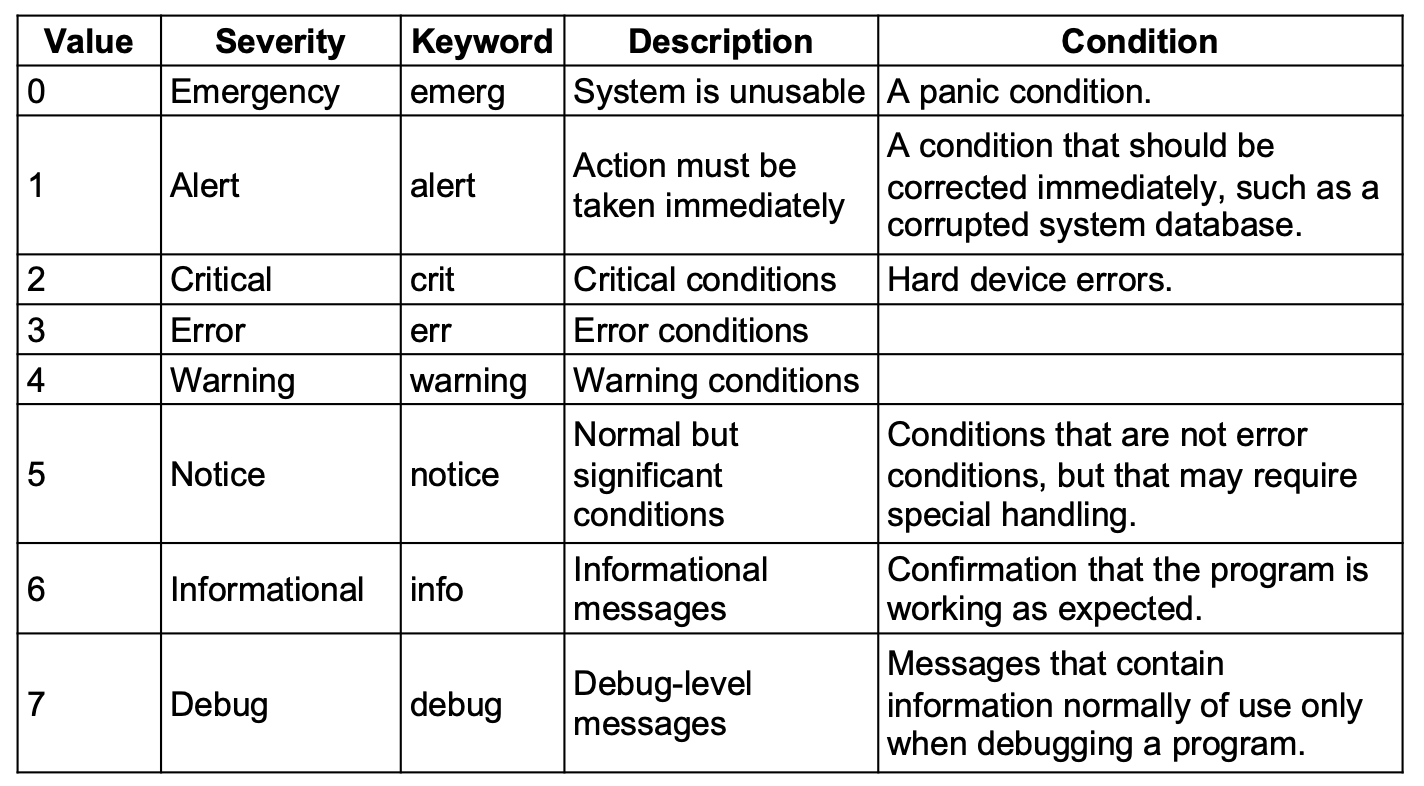
La lista delle severità:
journald
journald risulta essere il sistema di logging usato da systemd. Il demone manda dei messaggi ai file binari che possono essere letti col comando journalctl e, di default, sono cancellati ogni volta che la macchina è riavviata.
Footnotes
echo "to standard out" > &1echo "to standard err" > &2
 Nel filesystem Linux, tutto è visto come un file. I file sono detti regular files. Esistono inoltre:
Nel filesystem Linux, tutto è visto come un file. I file sono detti regular files. Esistono inoltre: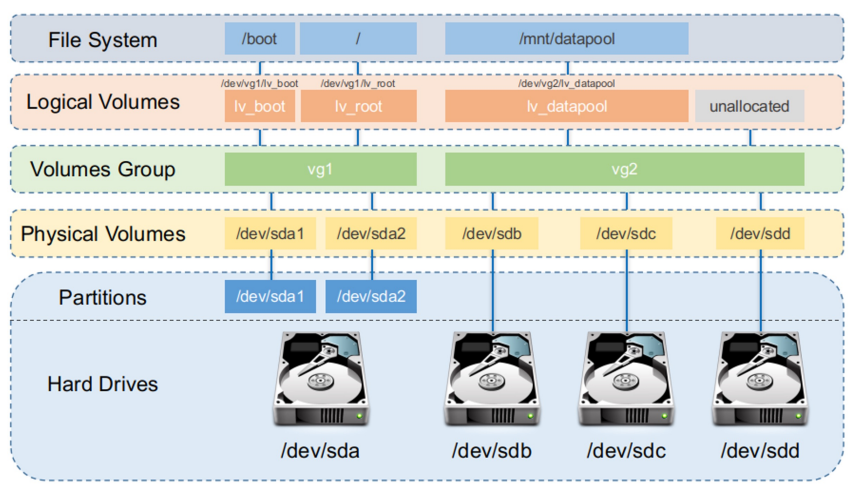 Utilizzando LUKS, inoltre, è possibile crittografare i volumi.
Utilizzando LUKS, inoltre, è possibile crittografare i volumi.
 Ciascuna unit è organizzata in sezioni:
Ciascuna unit è organizzata in sezioni: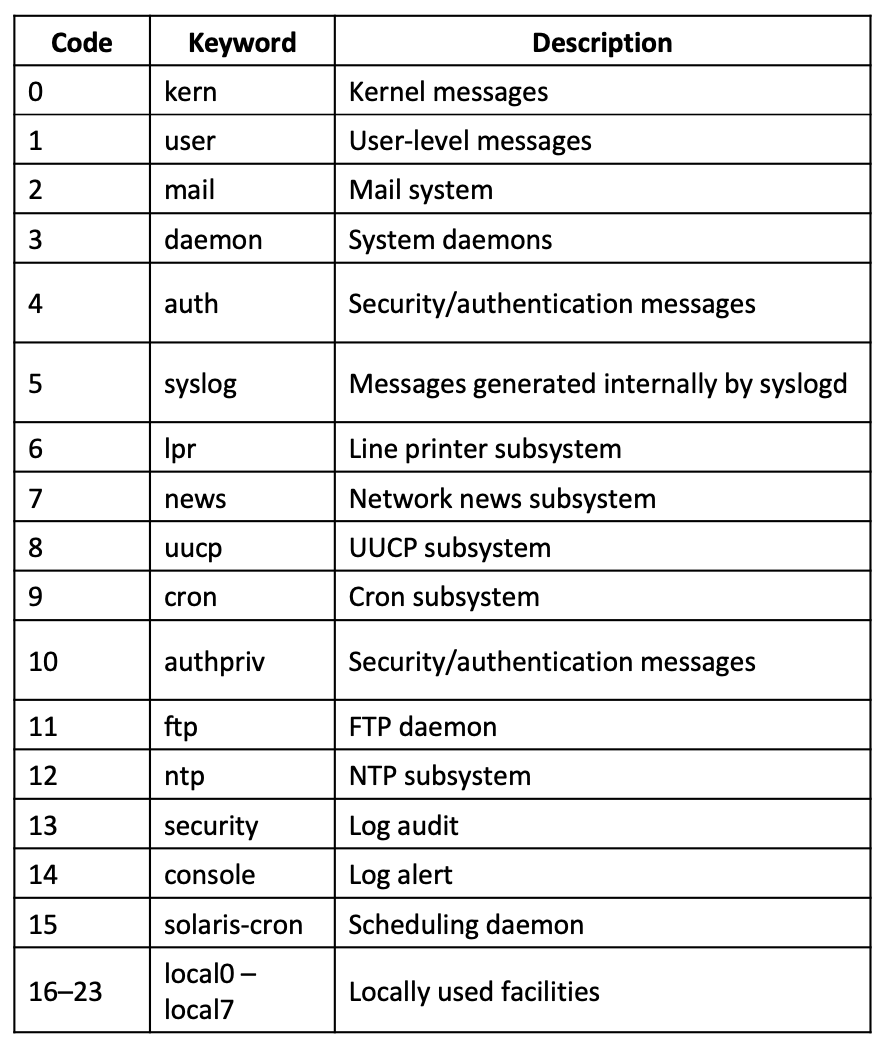 La lista delle severità:
La lista delle severità: