Questo argomento è stato trattato in networkSM.
Basi della crittografia
Quando si invia un messaggio crittografato, vi sono alcuni componenti che bisogna tenere in considerazione:
- il messaggio da trasferire, in chiaro;
- la chiave;
- il messaggio crittografato;
- l’algoritmo di crittografia utilizzato, senza il quale la chiave non avrebbe significato.
Crittografia simmetrica vs Crittografia asimmetrica
Esistono due tipologie di crittografia tra cui si fa distinzione: crittografia simmetrica e crittografia asimmetrica.
Crittografia simmetrica
La crittografia simmetrica, anche nota come crittografia a chiave simmetrica, è una modalità di implementazione della crittografia in cui si utilizza la stessa chiave per crittografare il messaggio in chiaro e decifrare il ciphertesto. Il vantaggio che deriva da questa implementazione è sicuramente la velocità, data dagli algoritmi a chiave simmetrica che, essendo generalmente più veloci e meno computazionalmente intensivi, risultano ideali per crittografare più velocemente grandi quantità di dati. D’altra parte, la gestione della chiave (key management) è un problema non da poco, poiché bisogna garantire che la chiave possa essere scambiata in modo sicuro e mantenuta segreta tra le entità comunicanti. Algoritmi comuni sono: AES, DES e 3DES.
Modalità di funzionamento e block cipher
Gli algoritmi a chiave simmetrica lavorano crittografando blocchi di bit alla volta, anziché operando bit per bit. In particolare, dato il valore di , si divide il messaggio da crittografare in blocchi grandi bit e si crittografa ciascun blocco in maniera indipendente. Ogni blocco del messaggio in chiaro viene mappato con un blocco, sempre di bit, di ciphertext e, scegliendo un mapping 1:1, si avrà un output diverso per ciascun input. Si osserva, così, che il mapping non è altro che una permutazione di tutti i possibili input; questo, con sufficientemente piccolo, rendere questo meccanismo vulnerabili agli attacchi a forza bruta con cui si può provare a decifrare il messaggio provando tutte le possibili combinazioni. Al contrario, avere delle tavole molto complesse in grado di fornire schemi sufficientemente robusti, è una soluzione piuttosto complicata da implementare, sia per la grande quantità di possibili input, sia per la necessità di dover rigenerare le tabelle se la chiave deve essere rigenerata. Per risolvere questi problemi, i block cipher sono delle funzioni che simulano tabelle con permutazioni randomiche. Il meccanismo impiegato segue queste fasi (prendendo come esempio ):
- si divide un blocco da 64 bit in 8 chunk più piccoli da 8 bit ciascuno;
- si processano 8 bit alla volta da tabelle più piccole e più gestibili;
- gli 8 output sono rimescolati per formare un nuovo blocco da 64 bitˆ[Viene scambiato non solo l’ordine dei blocchi, ma anche i bit all’interno dei blocchi vengono permutati.];
- si ripete il ciclo volte. La cosa più importante da ricordare è che blocchi in chiaro uguali potrebbero essere trasformati in blocchi cifrati sempre uguali. Questo può creare una falla che consentirebbe ad un osservatore di determinare il contenuto dei blocchi cifrati anche senza conoscere la chiave di crittografiaˆ[Chosen plain-text attack.]. Il pattern viene perciò nascosto senza dover creare una nuova chiave dopo la crittografia di ciascun blocco, randomizzando i dati in input. Il NIST ha pubblicato un documento contente degli standard, in cui sono dettagliate quattro modalità operative che coinvolgono i block ciphers, ciascuno che descrive una soluzione diversa per crittografare un blocco di ingresso; questi sono:
- ECB (Electronic Codebook Mode): ogni blocco è cifrato in maniera indipendente usando la stessa chiave; sebbene sia semplice e può supportare il parallelismo, non nasconde le ripetizioni nei dati, visto che blocchi di testo uguali producono sempre lo stesso testo crittografato;
- CBC (Cipher Block Chaining Mode): ogni blocco di testo in chiaro è messo in
XORcon il blocco di ciphertext precedente, prima di essere cifrato, mentre il primo blocco è messo inXORcon un particolare valore, detto intialization vector. In questo caso, le ripetizioni sono nascoste e blocchi di testo uguali non producono lo stesso ciphertext, perdendo però la possibilità di avere parallelismo - CFB (Cipher Feedback Mode): ogni blocco di testo crittografato è trasforamto in uno stream cipher. Cifra le parti di plaintext una alla volta e utilizza il ciphertext di un blocco come input del blocco successivo. Riesce a cifrare dati di qualsiasi lunghezza, ma la lunghezza del ciphertext è la stessa del plaintext;
- OFB (Output Feedback Mode): simile al CFB, da cui differisce per il fatto che, anziché usare il ciphertext generato precedentemente, si utilizza l’output cifrato del cifrario a blocchi (quindi prima di qualsiasi
XORcon il plaintext). Esistono ulteriori modalità: - PCBC (Propagating Cipher Block Chaining): non è una modalità utilizzata in combinazione con i block ciphers. Il suo funzionamento introduce una propagazione dell’errore^[La propagazione dell’errore è un fattore desiderabile sia perché consente di verificare l’integrità del messaggio - in caso di errori di trasmissione - sia perché consente di verificare tentativi di manomissione.] che influisce su tutti i successivi blocchi cifrati, in cui il primo blocco è messo in
XORcon un vettore di inizializzazione, mentre i successivi blocchi sono messi inXORsia col ciphertext precedente che con il plaintext precedente. Bisogna notare che, se con PCBC ogni errore influisce su tutti i blocchi di plaintext successivi in fase di decodifica, con CBC l’errore è propagato solo sul blocco di plaintext corrispondente e uno successivo, con CFB, OFB e CTR solo sul blocco corrispondente; - CTR (Counter Mode): è una modalità molto flessibile utilizzata frequentemente, che trasforma un cifrario a blocchi in un cifrario a flusso. Il funzionamento si basa su un valore iniziale, detto nonce che viene combinato ad un contatore incrementale e crea una serie unica di input per il cifrario a blocchi. Il nonce è concatenato col contatore e cifrato col cifrario a blocchi per produrre un output cifrato, che viene messo in
XORcon il blocco di plaintext per produrre un blocco di ciphertext. Offre parallelismo, ma diventa necessaria l’unicità del nonce (l’uso dello stesso nonce per diversi messaggi può compromettere la sicurezza).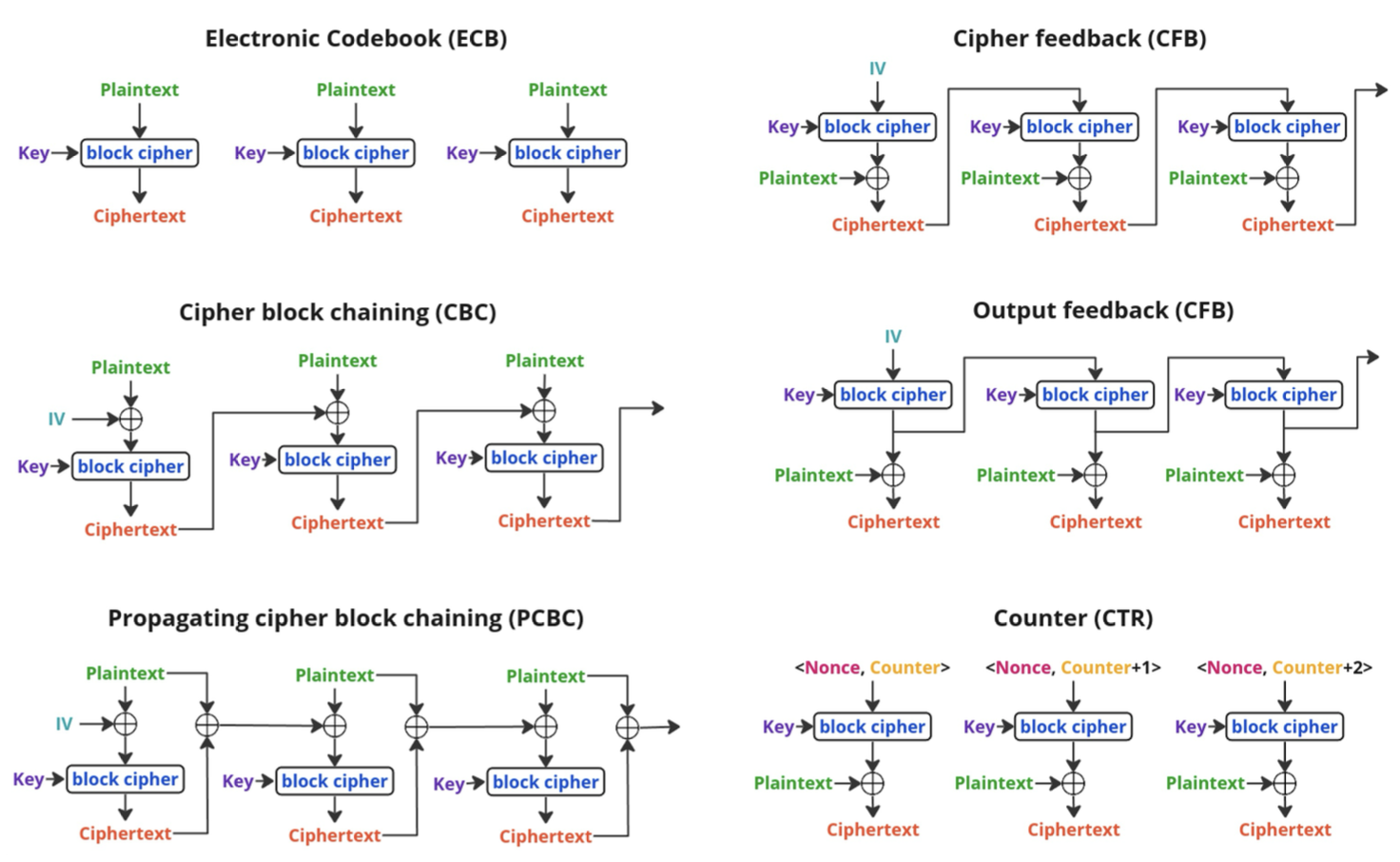 Con gli algoritmi come AES non si usa una tavola predeterminata ma si eseguono delle funzioni; la chiave dell’algoritmo determina il mapping e tutte le permutazioni che vengono usate con l’algoritmo.
Con gli algoritmi come AES non si usa una tavola predeterminata ma si eseguono delle funzioni; la chiave dell’algoritmo determina il mapping e tutte le permutazioni che vengono usate con l’algoritmo.
Crittografia asimmetrica
La crittografia asimmetrica, nota anche come crittografia a chiave pubblica, utilizza una coppia di chiavi per crittografare e decrittografare i messaggi. Nello specifico:
- una chiave pubblica, che può essere condivisa liberamente, viene utilizzata per crittografare i dati o per verificare la firma digitale;
- una chiave privata, mantenuta segreta, è utilizzata per decrittografare i dati o per creare una firma digitale.
Hashing
L’hashing è un processo che trasforma dei dati in input (detti messaggio) in una stringa a lunghezza fissa di caratteri, che tipicamente appare come una sequenza randomica di numeri e lettere. Funzioni di hash comuni sono:
- MD5, obsoleto e insicuro a causa di vulnerabilità e alta facilità con cui si producono collisioni;
- SHA-1, come MD5;
- SHA-256, considerato sicuro e ampiamente usato, parte della famiglia di algoritmi SHA-2;
- SHA-3, nuova aggiunta alla famiglia di algoritmi SHA, è il successore designato di SHA-2. Le proprietà di un hash:
- deterministico: lo stesso input darà sempre lo stesso risultato (lo stesso hash);
- lunghezza fissa: l’output di una funzione di hash è a lunghezza fissa, a prescindere dalla dimensione del dato in input;
- efficienza: il processo di generazione di un hash è veloce ed efficiente;
- pre-image resistance (one-way): dato un hash, non deve essere computazionalmente ragionevole ricostruire il dato che l’ha generato;
- piccoli cambiamenti producono grandi differenze: piccoli cambiamenti nei dati di origine producono cambiamenti molto significativi nel nuovo hash tanto da farlo sembrare non correlato con l’hash precedente alla modifica;
- resistenza alle collisioni: deve essere difficile trovare due input che producono lo stesso hash. Gli utilizzi comuni dell’hash:
- integrità dei dati, poiché se i dati vengono modificati durante la trasmissione, l’hash cambierà segnalando l’alterazione;
- data retrieval, visto che l’hashing è il pilastro fondamentale delle hash tables;
- firme digitali, perché l’hashing è usato nel processo di firma digitale, in cui l’hash del messaggio è crittografato con una chiave privata per provare origine e integrità di un messaggio;
- criptomoneta;
- password, anche se un database contenente password in forma di hash dovesse essere compromesso, ritornare alla password originale non sarebbe fattibile. Soprattutto in quest’ultimo caso, oltre all’hash, si utilizza il salt, cioè un valore casuale, aggiunto ai dati prima di eseguirvi la funzione di hashing. Il salt ha due scopi principali:
- impedisce che sia visibile il fatto che due password siano duplicate;
- incrementa la difficoltà di attacchi a dizionario poiché, dato un salt lungo bit, si ottiene che il numero di possibili password aumenta di un fattore .
Firma digitale
Il processo per firmare digitalmente un contenuto segue questi step:
- si considera il messaggio originale e si esegue una funzione di hash, producendo il digest;
- la chiave privata è poi usata per crittografare il valore dell’hash, creando la firma digitale;
- la firma digitale è poi aggiunta al messaggio, conservata oppure trasmessa separatamente, in base all’implementazione specifica. La verifica di una firma sfrutta l’uso di una chiave pubblica per decrittografare la firma, che rivela l’hash del contenuto. Si procede poi al confronto dell’hash ottenuto contro l’hash calcolato da zero a partire dal contenuto originale; se i due hash sono uguali, allora la firma è valida e questo implica:
- il messaggio non è stato alterato (integrità);
- la firma è stata creata con la relativa chiave privata della chiave pubblica di cui si è in possesso (autenticità);
- il firmatario non può negare di aver firmato il messaggio (non ripudiabilità). Inoltre, per evitare che il firmatario neghi la validità della firma a causa della scadenza o della revoca della chiave, si può aggiungere un timestamp da un’autorità fidata per il timestamping al momento della creazione della firma.
Certificati
Certificato: definizione
Un certificato digitale è un documento elettronico usato per provare il possesso di una chiave pubblica.
Un certificato include informazioni riguardo a:
- chaive;
- identità del possessore;
- la firma di un’entità che ha verificato il contenuto del certificato (issuer). Se la firma digitale è valida e l’autorità certificante (CA, certifying authority) è fidata (trusted), la chiave pubblica si può considerare autentica e appartiene alla persona o l’entità indicata nel certificato. Il contenuto di un certificato è il seguente:
- subject: la persona, organizzazione o dispositivo identificata dal certificato;
- issuer: l’autorità che verifica le informazioni e rilascia il certificato;
- serial number: un numero unico in grado di distinguere ogni certificato emeso da una certa CA;
- public key: la chiave pubblica che il certificato associa ad una entità;
- signature algorithm: l’algoritmo usato per creare la firma dell’issuer;
- issuer’s signature: la firma utilizzata per verificare che l’issuer ha firmato il certificato;
- validity period: la finestra temporale in cui il certificato può essere considerato valido;
- certificate policy: la policy sotto cui il certificato è stato rilasciato e lo scopo d’uso del certificato.
Certification Authority
Una CA è un’entità fidata che emette certificati digitali. Svolge tre compiti principali:
- identity verification, con cui verifica l’identità di chi richiede un certificato;
- certificate issuance, dopo la verifica dell’identità, la CA emette un certificato che contiene la chiave pubblica dell’entità e informazioni sull’identità;
- la CA firma il certificato usando la propria chiave privata, per garantirne l’autenticità. Inoltre, si può anche avere:
- certificate revocation, con cui, se la chiave privata associata al certificato è compromessa o se il certificato non è più necessario, la CA può revocarlo per impedirne l’uso^[Questo fa finire il certifcato nella CRL, Certificate Revocation List, oppure il suo stato viene reso non disponibile mediante l’Online Certificate Status Protocol (OCSP).];
- certificate renewal, con cui la CA può rinnovare il certificato quando ci si avvicina alla data di scadenza, in seguito ad una ri-verifica dell’identità;
- directory services, con cui la CA mantiene dictory di certificati con i relativi stati (valido, scaduto, revocato). Esistono diverse tipologie di CA:
- root certification authorities, alla cima della gerarchia, sono autorità altamente protette su sui si basa l’intera infrastruttura delle chiavi pubbliche (PKI);
- intermediate certification authorities, che mutuano la loro affidabilità dalle root CA e possono emettere certificati per conto delle root CA, creando un layer di buffer che aggiunge sicurezza^[Se una CA intermedia è compromessa, la CA root rimane sicura e vanno revocati solo i certificati rilasciati dalla CA intermedia.].
Le CA sono fondamentali per il modello di fiducia che si usa per la sicurezza delle transazioni online: le entità si fidano dei certificati poiché si fidano della CA che li ha emessi. I certificati delle CA sono firmati da una CA root, le quali sono incluse in una lista di certificati root aggiornata da produttori di software e di dispositivi.
Il formato più utilizzato per i certificati di chiave pubblica è
X.509(RFC5280).
Transport Level Security (TLS)
Esistono diversi approcci nel garantire la sicurezza sul web. Si può pensare di includere misure di sicurezza a livello di rete, a livello di trasporto e a livello di applicazione.
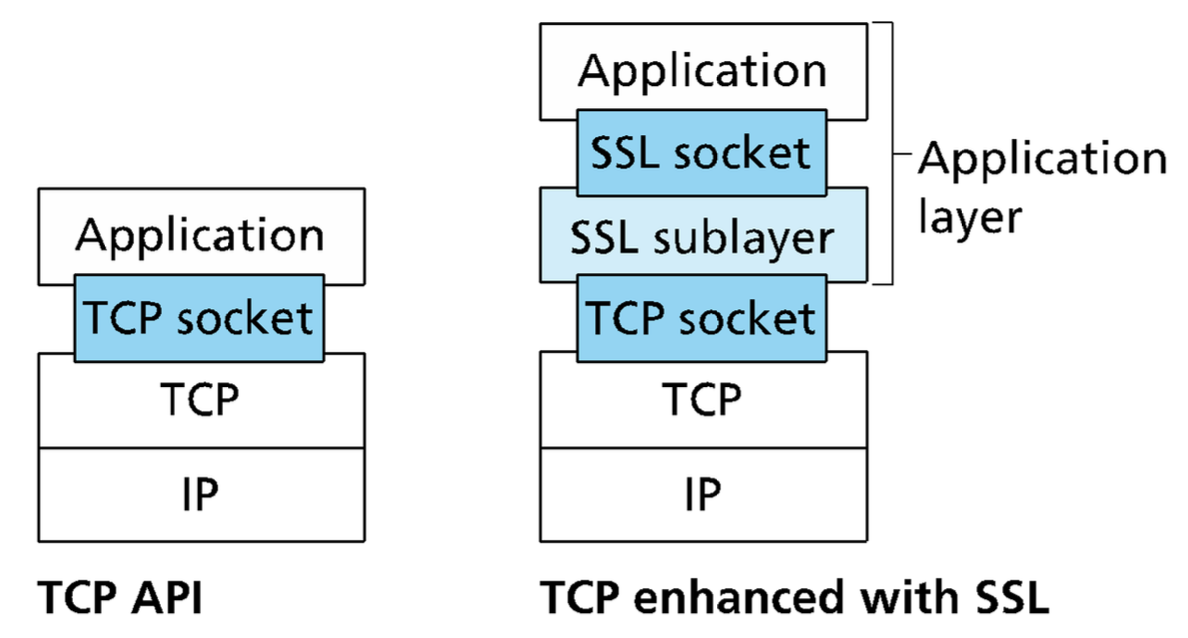
La scelta predominante è quella di implementare meccanismi di sicurezza al di sopra del livello di trasporto (TCP), con soluzioni come SSL (Secure Sockets Layer) e TLS (Transport Layer Security), con quest’ultimo che nasce come un’evoluzione del primo, ormai deprecato dall’IETF.
TLS è un servizio general-purpose che viene implementato con un set di procolli che fanno affidamento su TCP. Ci sono due scelte di implementazione:
- TLS può essere fornito come parte di una suite di protocolli di base e quindi è trasparente all’applicazione;
- TLS può essere incorporato in pacchetti specifici, come nel caso di browser e Web Server.
Lo scopo di TLS è quello di usare TCP per fornire un servizio affidabile e sicuro, end to end; non è rappresentato da un singolo protocollo ma da una serie di strati di protocolli, la cui base è rappresentata da TLS Record Protocol che fornisce servizi di sicurezza di base a vari protocolli di livelli più alto (eg. HTTP). Fanno parte di TLS i protocolli:
- protocollo di handshake;
- il protocollo di change cipher spec;
- il protocollo di Alert.
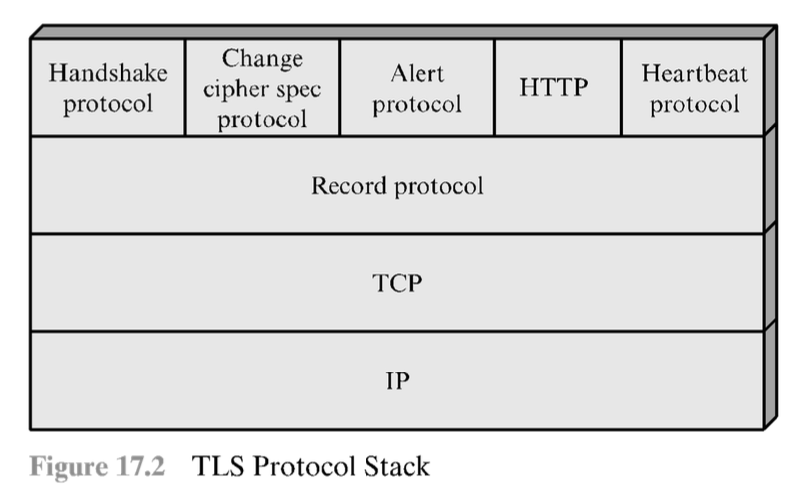
In TLS, ogni connessione è un trasporto che fornisce un tipo di servizio adeguato (relativamente ad affidabilità, integrità dei dati etc), viste da TLS come relazioni peer to peer (senza intermediari) e transitorie. Ogni connessione è poi associata ad una sessione.
Una sessione è un’associazione tra un client e un server, creata grazie al protocollo di handshake. Ogni sessione definisce un insieme di parametri crittografici di sicurezza, che possono essere condivisi tra più sessioni per evitare la negoziazioni di nuovi parametri per ogni connessione, essendo un’operazione esosa. Ogni sessione ha un certo numero di stati associati ad essa che, una volta stabilita la sessione, regolano lettura e scrittura (quindi invio e ricezione dei dati). Un elenco di questi parametri:
- session identifier: una sequenza arbitraria scelta dal server per identificare uno stato di una sessione attiva o che può essere ripresa;
- peer certificate: un certificato X509.v3 dell’altro peer;
- compression method: l’algoritmo usato per comprimere i dati prima della crittografia;
- cipher spec: specifica l’algoritmo per la crittografia dei dati e l’algoritmo di hash usato per il calcolo del MAC;
- master secret: un segreto lungo 48 byte condiviso tra client e server;
- isResumable: un flag che indica se la sessione può essere usata per inizializzare nuove connessioni.
Gli stati sono invece:
- server and client random: delle sequenze di byte scelte dal server e dal client per ogni connessione;
- server write MAC secret: la chiave segreta utilizzata per le operazioni MAC sui dati inviati dal server;
- client write MAC secret: la chiave simmetrica usata nelle operazioni MAC sui dati inviati dal client;
- server write key: la chiave simmetrica per i dati crittografati dal server e decrittografati dal client;
- client write key: la chiave simmetrica per i dati crittografati dal client e decrittografati dal server;
- initialization vectors: quando un cifrario a blocchi CBC è usato, un vettore di inizializzazione viene mantenuto per ogni chiave, con il primo inizializzato dal protocollo di handshake;
- sequence number: ogni parte mantiene una sequenza separata di numeri di messaggi inviati e ricevuti per ogni connessione.
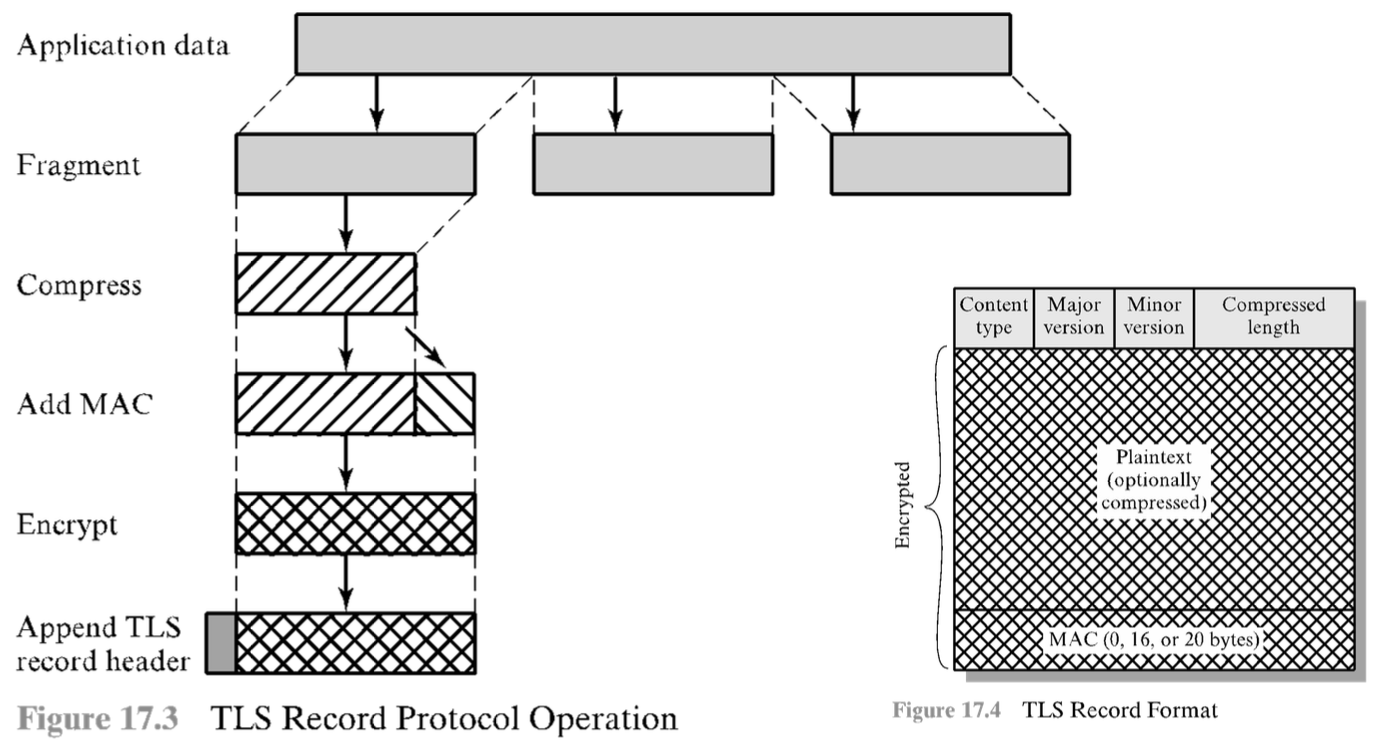
TLS Record Protocol
Il protocollo TLS Record fornisce due servizi alle connessioni TLS:
- confidenzialità: il protocollo di handshake definisce una chiave segreta condivisa che è usata per la crittografia convenzionale dei payload TLS;
- integrità dei messaggi: il protocollo di handshake stabilisce anche una chiave condivisa segreta che viene usata per formare i MAC (Message Authentication Code).
Questo protocollo prende un messaggio da trasmettere, lo frammenta in blocchi più gestibili, opzionalmente comprime i dati, applica un MAC, crittografa, inserisce un’intestazione e trasmette il risultato in un segmento TCP; dall’altro alto, i dati sono decrittografati, verificati, decompressi e riassemblati, prima di essere passati al livello superiore.
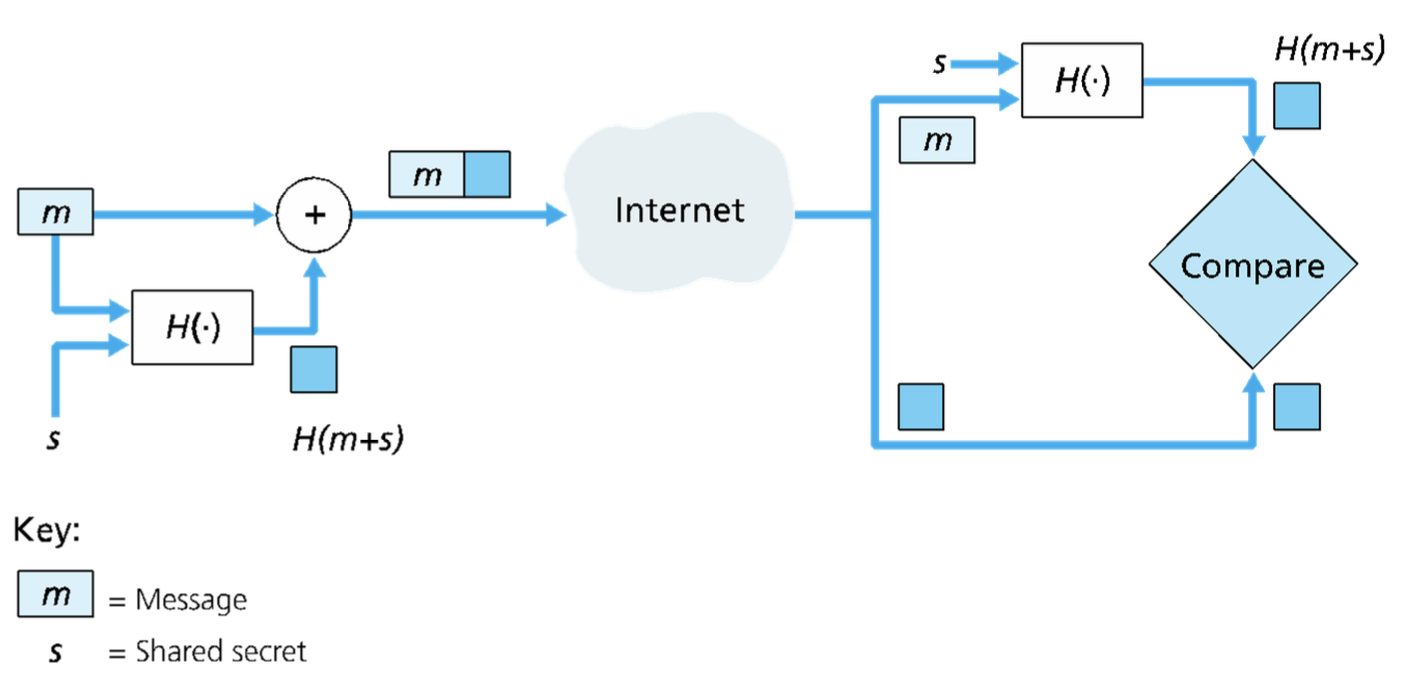
Message Authentication Code (MAC)
- Si crea un messaggio e se ne calcola l’hash ;
- si aggiunge l’hash al messaggio, creando un messaggio esteso e si invia il messaggio esteso;
- il ricevente riceve un messaggio esteso e calcola . Se , allora è tutto okay.
Questo approccio è vulnerabile ad attacchi di tipo man in the middle. Per avere anche l’integrità del messaggio, oltre alle funzioni crittografiche di hash, si una un segreto condiviso , detto authentication key, che è una stringa di bit. Questo fa modificare lo schema, che ora prevede l’aggiunta del segreto al messaggio, prima di calcolare l’hash:
Alert Protocol
Il protocollo di alert viene usato per inviare alert relativi a TLS all’entità. Come con altre applicazioni che usano TLS, i messaggi sono compresi e crittografati, come specificato dallo stato corrente. Ogni messaggio del protocollo consiste di due byte:
- il primo ha valore warning o fatal ed esprime la severità del messaggio. Se il livello è fatale, la connessione è terminata da TLS immediatamente e altre connessioni sulla stessa sessione possono continuare, ma nessuna nuova connessione su quella sessione può essere stabilita;
- il secondo contiene un codice che indica l’alert specifico.
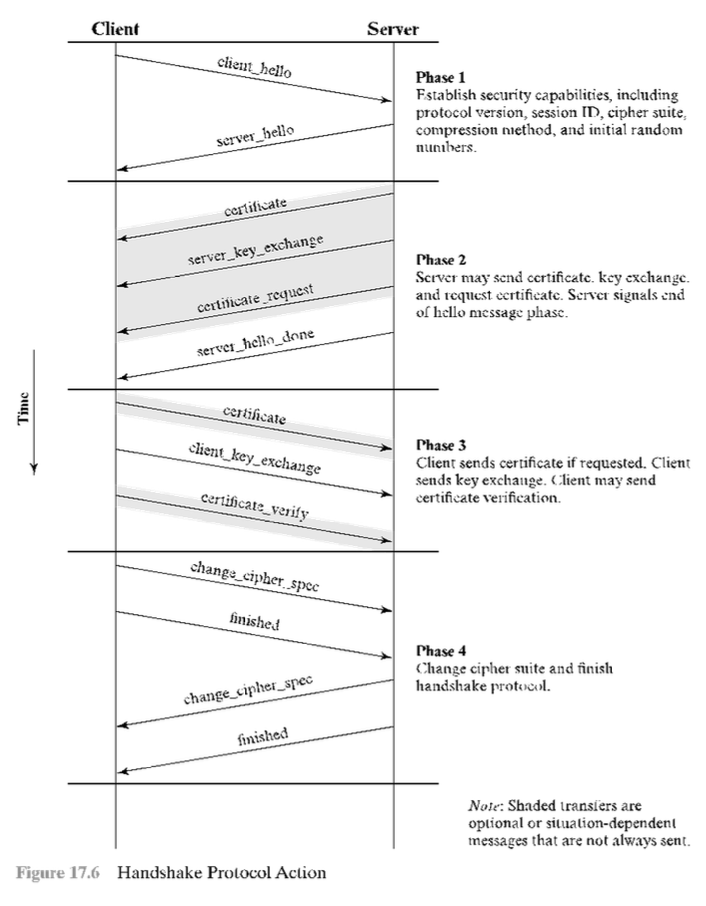
Handshake protocol
La parte più complicata di TLS è il protocollo di handshake, che permette al server e al client di autenticarsi e di negoziare gli algoritmi di crittografia e per il MAC, insieme alle chiavi crittografiche da usare per proteggere i dati inviati in un record TLS. Per questo, è usato prima di ogni trasferimento dati.
Si compone di una serie di messaggi che sono scambiati tra client e server:
- si usa per stabilire una connessione logica e per stabilire le proprietà di sicurezza da associarvi. Dopo aver inviato il messaggio di
client_hello, il client aspetta il messaggioserver_hello, che contiene gli stessi parametri diclient_hello. Si nota che lo scambio è avviato dal client e contiene i parametri:- version: la versione di TLS recepita dal client;
- random: una struttura random generata dal client, usata nello scambio di chiavi per evitare attacchi di tipo replay^[Si tratta di un tipo di attacco in cui un attaccante intercetta e ritrasmette dati validi e autenticati per ingannare il destinatario e avere accesso non autorizzato. Il random protegge da questo tipo di attacchi poiché genera un nuovo random per ogni sessione, non permettendo a quelli vecchi di funzionare.];
- session ID: un identificativo di sessione a lunghezza variabile. Se impostato a zero, indica che si vuole iniziare una nuova connessione su una nuova sessione, in altro caso si vuole aggiornare i parametri della connessione oppure creare una nuova connessione su quella sessione;
- ciphersuite: una lista di algoritmi crittografici supportati dal client, in ordine decrescente di preferenza. Per ogni elemento, si specificano sia un algoritmo di scambio chiavi, sia un CipherSpec;
- compression method: una lista di modalità di compressione che il client supporta.
- i dettagli della fase 2 dipendono dallo schema di chiave pubblica che è usato: in alcuni casi, il server passa un certificato al client, altre informazioni aggiuntive sulla chiave e la richiesta di un certificato dal client, ma si conclude sempre con un messaggio richiesto, detto
server_done, che indica la fine delserver_helloe relativi messaggi. Dopo aver inviato il messaggio, il server attende una risposta del client; - a questo punto, il client deve verificare che il server abbia fornito un certificato valido, se richiesto e che i parametri del
server_hellosiano accettabili. In base allo schema di chiave pubblica, il client invia uno o più messaggi al server; - l’ultima fase completa la creazione di una connessione sicura. Il client invia un messaggio di tipo
change_cipher_spece copia ilCipherSpecin attesa nelCipherSpeccorrente. Questo non è considerato un messaggio che fa parte del protocollo di handshake, ma viene inviato usando il protocollo Change Cipher Spec. Il client invia immediatamente il messaggio finito con i nuovi algoritmi, chiavi e segreti e server per verificare lo scambio di chiavi e che il processo di autenticazione abbia avuto successo.
TLS Heartbeat protocol
Con heartbeat si intende un segnale periodico generato dall’hardware o dal software per indicare una normale operatività o per sincronizzare altre parti del sistema; con protocollo heartbeat quindi si identifica un protocollo usato per monitorare la disponibilità di un’entità.
Nel caso di TLS, il protocollo di heartbeat viene eseguito al di sopra del protocollo di record e consiste in due tipi di messaggi:
heartbeat_request, che può essere inviato in ogni momento e a cui bisogna rispondere con un messaggio di tipoheartbeat_response;heartbeat_response.
Questo protocollo consente di essere sicuri, lato mittente, che il destinatario sia ancora attivo, anche se non vi è stata attività sulla connessione TCP sottostante da un po’ di tempo.
Si occupa, inoltre, di generare attività sulla connessione nei periodi di idle, così da evitare una connessione da parte di un firewall che non permette le connessioni in idle.
HTTPS
HTTPS sta per HTTP over SSL e si riferisce ad una combinazione di HTTP e SSL per implementare comunicazioni sicure tra un browser e un server Web^[È compito di quest’ultimo garantire il supporto all’HTTPS.]. Viene documentato in RFC2818 che si riferiscce a HTTP Over TLS e non esiste nessuna differenza sostanziale tra i due (entrambe le implementazioni sono note come HTTPS).
Nel contesto di HTTPS, l’entità che agisce da client HTTP è anche il client TLS, che avvierà anche la connessione al server inviando il messaggio TLS client_hello sulla porta adeguata, per avviare l’handshake. Al termine dell’handshake, il client inizierà ad inviare la richiesta HTTP e tutto il traffico HTTP verrà inviato come traffico TLS e il comportamento “standard” di HTTP è rispettato, incluse le connessioni persistenti.
Quando si chiude la connessione, si invia il messaggio HTTP per la chiusura della connessione; nel contesto di HTTPS, però, occorre chiudere anche la connessione TLS, che implica chiudere la connessione TCP sottostante. Con TLS, dunque, il modo appropriato per chiudere la connessione è quello di usare il protocollo di alert per inviare un messaggio di tipo close_notify.
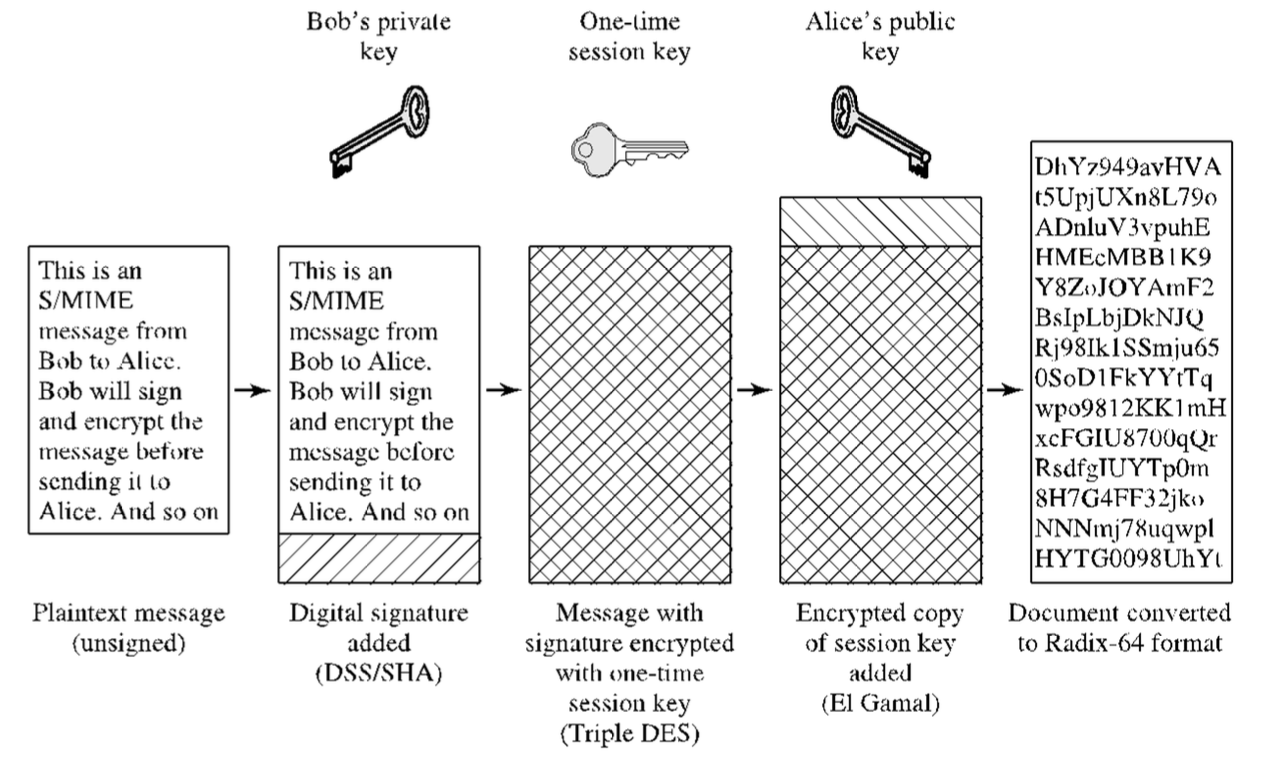
S/MIME
S/MIME (Secure Multipurpose Internet Mail Extension) è un miglioramento relativo alla sicurezza del formato MIME e si definisce come un insieme addizionale di tipi MIME. Vi è il supporto a nuove funzioni, quali:
- enveloped data, cioè contenuto crittografato di qualsiasi tipo e chiavi di crittografia per uno o più destinatari;
- signed data, cioè una firma digitale creata prendendo l’hash del contenuto e cifrandolo con la chiave primaria del firmatario, codificata in base64^[Questa tipologia di contenuto è visibile solo da destinatri con support a S/MIME.].
Virtual Private Network (VPN)
La VPN nascono per consentire ad istituzioni la cui rete si estende su più regioni geografiche di avere comunicazioni sicure senza fare il deploy di una rete fisica standalone, ma sfruttando reti pubbliche (eg. Internet) che sono non sicure.
Protocollo IPSec
Il protocollo IPSec viene utilizzato per implementare VPN; si compone di due protocolli principali:
- Authentication Header (AH) protocol, che fornisce l’autenticazione della fonte e l’integrità dei dati, ma non la confidenzialità;
- Encapsulation Security Payload (ESP) protocol, che fornisce l’autenticazione della sorgente, l’integrità dei dati e la confidenzialità.
Quando un’entità sorgente IPSec invia un datagramma sicuro ad un destinatario, lo fa esclusivamente o con il protocollo AH o con il protocollo ESP; chiaramente, dal momento in cui si ricerca la confidenzialità dei dati, il protocollo ESP è molto più usato di AH. Prima di inviare un datagramma, però, le entità coinvolte nella comunicazione creano una connessione logica a livello di rete, detta security association (AS), unidirezionale (dalla sorgente alla destinazione)^[Se si vuole scambiare in entrambe le direzioni, è necessario dunque creare due SA.].
Funzionamento di IPSec
Il router manterrà informazioni sullo stato della SA, che includono:
- Security Parameter Index (SPI), un identificativo a 32 bit della SA;
- l’interfaccia sorgente della SA e l’interfaccia destinazione della SA;
- il tipo di crittografia usata;
- la chiave di crittografia;
- il tipo di controllo di integrità;
- la chiave di autenticazione.
Quando il router deve costruire il datagramma IPSec da inviare sulla SA, controlla queste informazioni per determinare come autenticare e crittografare il datagramma. L’insieme di tutte le informazioni delle SA sono salvate nel Security Association Database (SAD), una struttura dati contenuta nel kernel del’OS.
Esistono due tipologie di pacchetti:
- tunnel mode;
- transport mode.
Nella tunnel mode, il router converte il datagramma originale in un datagramma IPSec nel seguente modo:
- aggiunge alla coda del datagramma un campo ESP trailer;
- crittografa il risultato con l’algoritmo e la chiave specificata nella SA;
- aggiunge all’inizio del del pacchetto crittografato un campo, detto ESP header a formare l’enchilada;
- crea un MAC di autenticazione per l’enchilada usando l’algoritmo e la chiave specificata nella SA. Per farlo, aggiunge una chiave MAC segreta all’enchilada e calcola poi l’hash del risultato;
- aggiunge il MAC alla coda dell’enchilada per formare il payload;
- crea una nuova intestazione IP con i campi classici da aggiungere prima del payload.
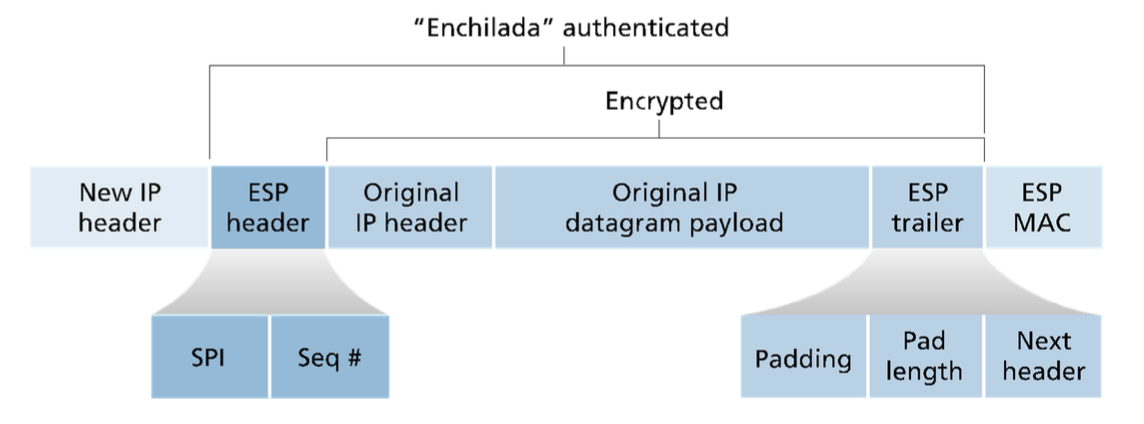
Osservando la struttura di un datagramma IPSec, si notino i campi dell’ESP trailer. Si ricorda che i cifrari a blocchi, per funzionare, richiedono che il messaggio sia un multiplo della lunghezza del singolo blocco. Per renderlo possibile, si usa il padding per far sì che si completi il blocco, di cui si specifica la dimensione nel campo pad-length. Il campo next-header specifica, invece, il tipo di dato contenuto nel payload (eg. un datagramma UDP). Il sequence number si usa per proteggersi dai replay attack.
Dal punto di vista del destinatario, si applica il processamento del datagramma IPSec con il codice 50 nel tipo di contenuto nell’intestazione IP. Il processo prevede:
- si determina a quale SA appartiene il datagramma, mediante l’SPI;
- si calcola il MAC dell’enchilada e si verifica che il MAC sia compatibile con il valore contenuto nel campo ESP MAC. Se coincidono, significa che il dato non è stato alterato;
- si controlla il sequence number per verificare che il datagramma sia nuovo;
- si decrittografa l’unità usando l’algoritmo di decrittografia e la chiave associata alla SA;
- si rimuove il padding e si estrae il contenuto originale del datagramma;
- si inoltra il datagramma a destinazione.
Non tutto il traffico deve essere protetto con IPSec; parte di questo può essere processato su reti pubbliche. Per distinguere se un datagramma deve essere protetto o meno, si fa riferimento ad un’altra struttura dati, la Security Policy Database (SPD), che indica il tipo di datagramma (in funzione di indirizzo IP sorgente, indirizzo IP destinazione e il tipo di protocollo) che deve essere processato con IPSec ed, eventualmente, quale SA deve essere usata.
SAD vs SPD
La SPD indica cosa fare con un datagramma, la SAD indica come farlo.
SSH
SSH (acronimo di Secure SHell) è un approccio software alla sicurezza di rete. Ogni volta che un dato è inviato sulla rete, SSH lo crittografa in modo automatico, offrendo crittografia in modo trasparente sfruttando algoritmi moderni e sicuri.
SSH segue un’architettura client-server, in cui un server accetta o rifiuta connessioni ai computer host. L’utente esegue, invece, dei client SSH, generalmente su computer diversi, per fare delle richieste al server SSH; tutte le comunicazioni sono crittografate e protette dalla modifica.
Si rammenta che SSH non è una vera shell e non è un interprete dei comandi. Piuttosto, si occupa di creare un canale per eseguire delle shell su un computer remoto, con crittografia end-to-end tra i due host. Tuttavia, SSH non rappresenta una soluzione completa per la sicurezza, non proteggendo ad esempio da intrusioni oppure attacchi di tipo DOS. Infatti, SSH è un protocollo e non un prodotto, in grado di coprire autenticazione, crittografia e integrità dei dati trasmessi sulla rete, creando delle connessioni tra computer in grado di garantire che entrambe le entità siano autentiche e che i dati arrivino non modificati e non letti da entità non autorizzate.
Esistono due versioni del protocollo SSH:
- SSH-1: il protocollo originale con serie limitazioni, il cui uso non è più consigliato;
- SSH-2: il protocollo più sicuro e utilizzato oggi, i cui standard sono definiti dall’IETF. Utilizza diversi algoritmi rispetto a SSH-1 per la crittografia e l’autenticazione.
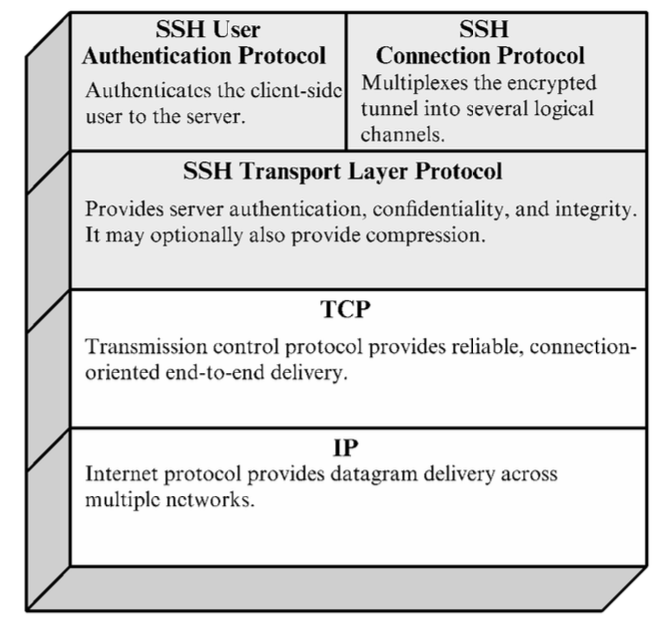
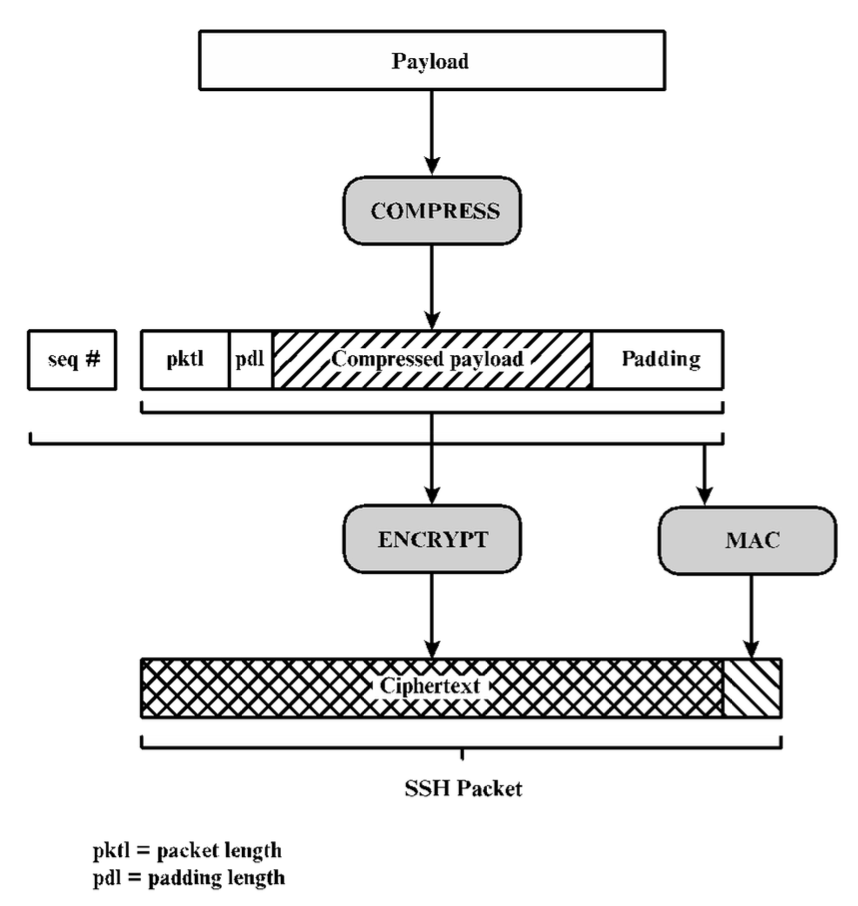
SSH è gestito come una serie di tre protocolli che vengono eseguiti sopra TCP:
- transport layer protocol, fornisce autenticazione col server, confidenzialità dei dati e l’integrità dei dati mediante forward secrecy^[È la garanzia che le chiavi di sessione, utilizzate per cifrare le comunicazioni, non possano essere compromesse, anche se la chiave privata del server viene compromessa in futuro.];
- user authentication protocol;
- connection protocol, con cui si fa il multiplexing di più connessioni logiche su una singola connessione SSH di base.
SSH è anche molto flessibile: può essere utilizzato, oltre che per eseguire comandi e script su un’altra macchina, anche per fare login e trasferimento sicuro di file.
Autenticazione in SSH
SSH consente diversi meccanismi di autenticazione; il più sicuro è basato sull’uso di chiavi anziché di password. Il loro utilizzo prevede l’uso di un authentication agent in abbinata a SSH, offrendo anche il vantaggio di autenticarsi su più computer senza ricordarsi tutte le password o inserirle ripetutamente.
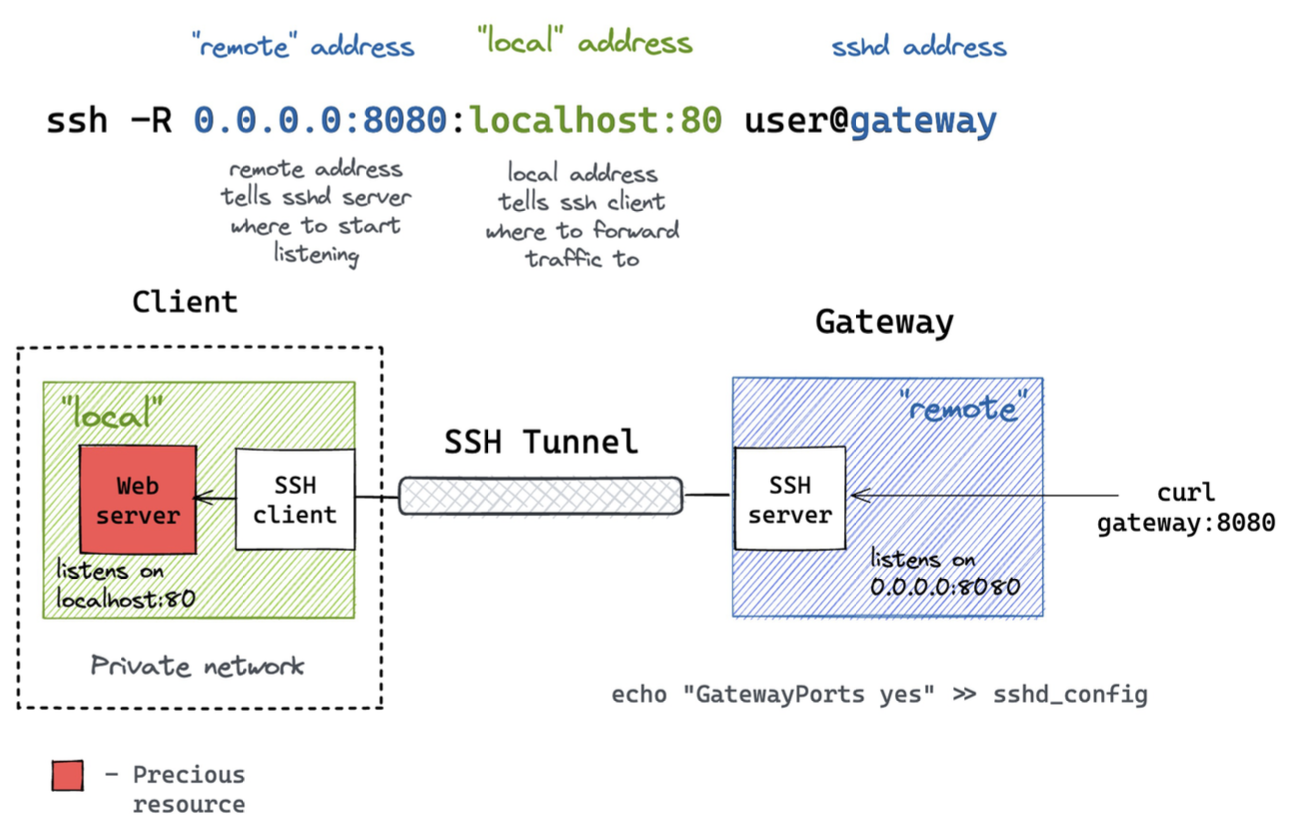
SSH Tunnel & Port Forwarding
Il port forwarding consente di convertire connessioni TCP non sicure in connesisoni SSH sicure. Questa operazione è anche nota come SSH tunneling.
SSH supporta due tipi di port forwarding:
- local forwarding;
- remote forwarding.
Nel caso del forwarding locale, SSH intercetta del traffico selezionato, a livello applicativo, e lo reindirizza da una connessione TCP non sicura ad un tunnel SSH, sicuro. In questo scenario, l’inizializzatore è la macchina client, su cui viene eseguito il comando SSH. Quando il traffico arriva su una certa porta, su cui il client è in ascolto; il traffico è poi inoltrato mediante il tunnel SSH ad una specifica porta sul server remoto^[Il server SSH remoto può essere anche un bastion host e non essere installato sulla stessa macchina su cui la risorsa a cui si vuole accedere risiede.]. È la soluzione scelta per accedere a servizi interni su una macchina remota dalla macchina locale, oppure per avere connessioni o trasferimenti di file sicuri mediante un server intermediio.
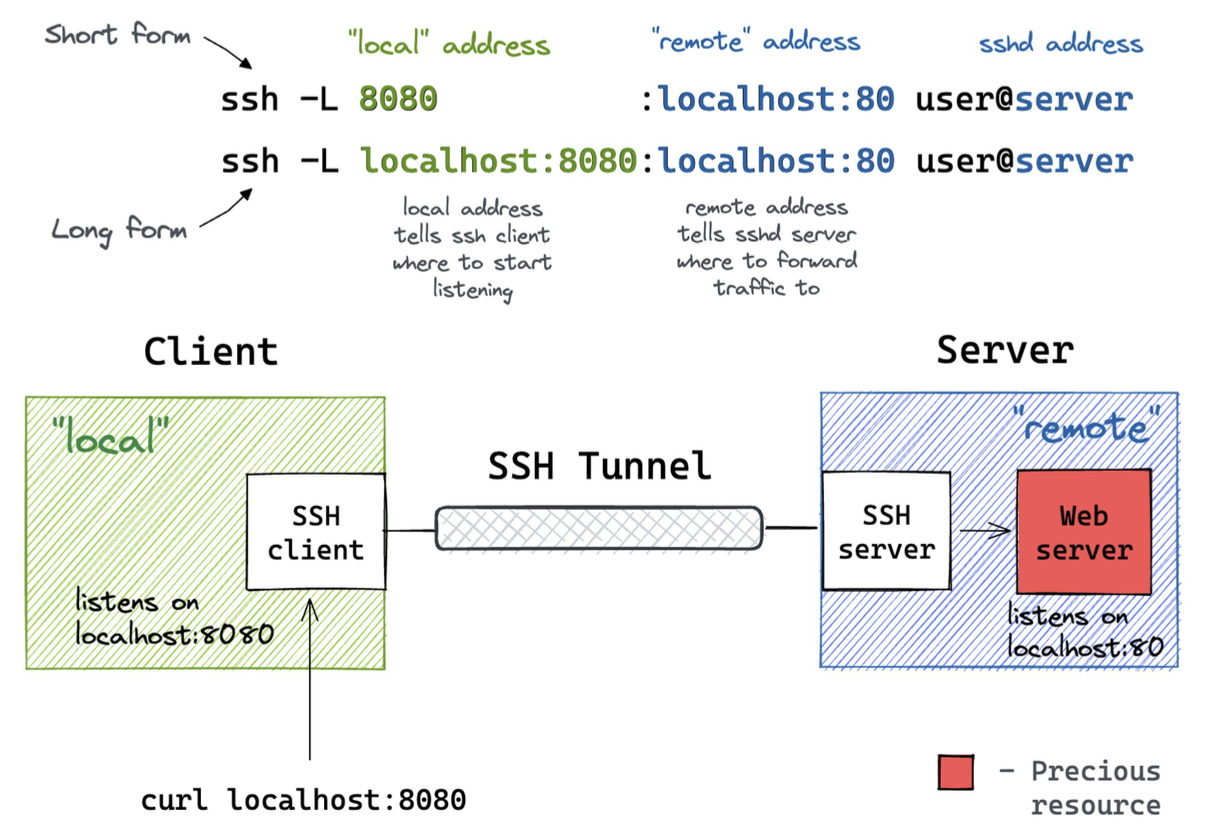
Nel caso del forwarding remoto, la direzione dello scambio è invertita. L’inizializzatore viene rappresentato dal server, in ascolto su una certa porta. Quando una connessione arriva alla porta remota del server, viene inviata sul tunnel SSH ad una porta precisa della macchina locale. Questa soluzione si adotta quando, ad esempio, si vuole concedere l’utilizzo ad un certo servizio sulla macchina locale.