Questo argomento è stato trattato in networkSM.
Introduzione al Network Management
Il network management è il processo di amministrazione e monitoraggio di reti di computer, col fine di ottenere delle performance ottimali, sicurezza e disponibilità delle risorse di rete. I compiti più frequenti sono:
- individuazione delle falle e risoluzione;
- monitoraggio delle prestazioni;
- gestione delle configurazioni;
- gestione della sicurezza;
- pianificazione di aspetti sulla capacità. Si tratta di una pratica importante che ha, come fine le seguenti funzioni principali:
- fault management: identificare e risolvere problemi di rete come interruzioni di collegamenti e colli di bottiglia nelle prestazioni;
- performance management: monitoraggio di metriche come uso di banda, latenza e perdita di pacchetti per garantire il grado di prestazione ottimale;
- configuration management: configurazione e gestione dei dispositivi di rete e delle configurazioni per efficientare le operazioni e la sicurezza;
- security management: implementazione di misure di sicurezza per proteggere la rete da minacce di vario tipo;
- accounting management: tracciamento e analisi dell’uso delle risorse per identificare potenziali problemi e ottimizzare l’allocazione di risorse. Le funzioni principali della Newtork Management and Security sono:
- scoperta ed inventario dei dispositivi: scoperta e mapping automatico dei dispositivi di rete per una panoramica più dettagliata;
- monitoraggio delle prestazioni: monitoraggio di varie metriche di rete (utilizzo di banda, latenza, perdita di pacchetti…);
- alert e notifica: capacità di generare alert sulla base di soglie predefinite oppure pattern di attività non usuali, consentendo l’identificazione proattiva dei problemi;
- report e analitica: capacità di generare dei report e analizzare dati storici per identificare dei trend, ottimizzare le prestazioni e pianificare aggiornamenti futuri;
- gestione della configurazione: gestione della configurazione dei dispositivi in modo centralizzato, garantendo consistenza e semplificando rilasci e aggiornamenti.
Software utilizzati
Per adempiere a questi scopi, si utilizzano diverse tipologie di software:
- tool per il monitoraggio della rete: per il monitoraggio di traffico e prestazioni in tempo reale;
- tool per la gestione della configurazione: automazione della configurazione dei dispositivi, in modo che sia consistente ed efficiente;
- security information and event management (SIEM): analisi di dati di sicurezza per rilevare minacce;
- network traffic analysis tools (NTA): per l’analisi di pattern del traffico di rete per rilevare anomalie e potenziali rischi di sicurezza;
- patch management tools: per automatizzare il processo di rilasciare aggiornamenti software e patch di sicurezza ai dispositivi di rete.
Strategie per l’ottimizzazione delle prestazioni
Diverse strategie possono essere applicate per ottimizzare le prestazioni di una rete. Tra queste:
- shaping del traffico: consiste nell’assegnare priorità differente a uno specifico tipo di traffico;
- Quality of Service (QoS): implementazione di meccanismi per garantire un certo quantitativo di banda o una certa latenza per applicazioni critiche;
- ottimizzazione di banda: identificazione e risoluzione di colli di bottiglia, insieme all’ottimizzazione delle risorse di rete per migliorare l’utilizzo di banda;
- network segmentation: creazione di divisione logiche nella rete per isolare il traffico e migliorare la sicurezza e le prestazioni;
- manutenzione regolare: svolgimento di manutenzione preventiva come aggiornamento dei dispositivi e revisioni delle configurazioni per garantire prestazioni ottimali.
Componenti chiave dell’architettura di rete
Una rete è composta dai seguenti elementi:
- dispositivi;
- protocolli: insieme di regole e procedure utilizzate per consentire la comunicazione tra più dispositivi in una rete;
- topologie: layout fisici o logici della rete che specificano come sono collegati i vari dispositivi;
- sicurezza: misure implementate per salvaguardare la rete da accessi non autorizzati.
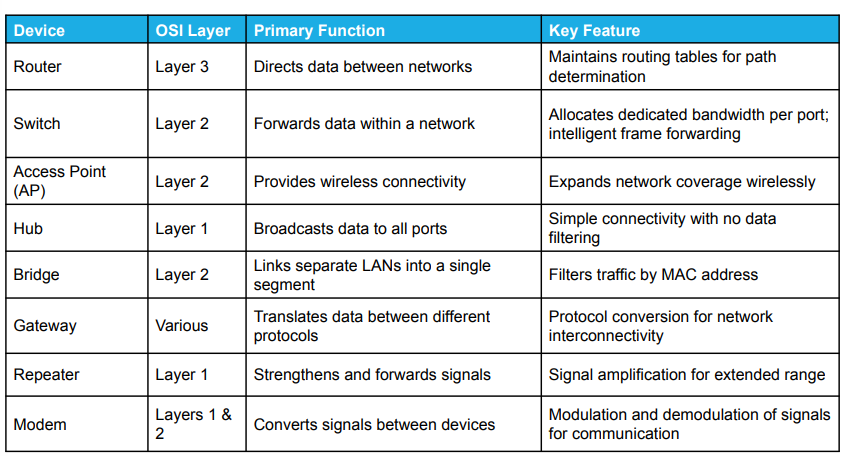
Topologie di rete
- topologia a bus: tutti i dispositivi sono collegati ad un cavo centrale. È facile da configurare ma è molto soggetta a guasti di tipo single points of failure;
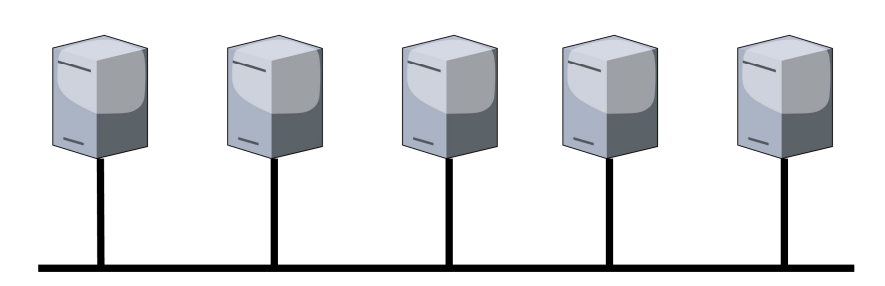
- topologia a stella: tutti i dispositivi sono collegati ad un centro, dove vi è un hub o uno switch. Consente un maggior grado di prestazione e una risoluzione dei problemi più facile, ma richiede un dispositivo centrale;
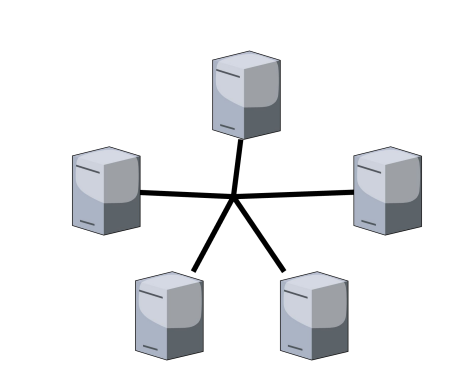
- topologia mesh: i dispositivi comunicano direttamente tra di loro, offrendo ridondanza e resilienza ai guasti, ma richiede una configurazione e una gestione più complesse;
- topologia ad anello: i dispositivi sono collegati ad anello chiuso, con il traffico che scorre in una direzione. Pur offrendo ridondanza, il collegamento può cadere se un singolo dispositivo è guasto.
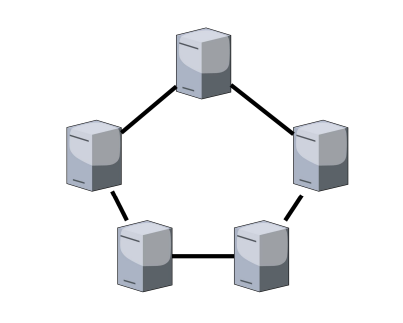
Architetture di rete
- client-server: un server centrale fornisce risorse e servizi ai dispositivi client, offrendo una gestione centralizzata ma dipendente dal server;
- peer-to-peer (p2p): i dispositivi comunicano e condividono risorse tra di loro. Garantiscono semplicità ma sono privi di un controllo centralizzato e di sicurezza;
- cloud-based: le risorse di rete e i servizi sono hostati sul cloud, offrendo flessibilità, scalabilità, necessitando meno di risorse di proprietà^[In gergo, on-premise infrastructure needs.]. La scelta dell’architettura di rete più appropriata è dettata da alcuni fattori:
- dimensione della rete e sua complessità: è necessario considerare la scala e la complessità della rete per determinare il livello di gerarchie e di sicurezza necessario;
- requisiti di prestazioni: è necessario valutare la banda, la latenza e l’affidabilità dei requisiti sulla base delle applicazioni critiche e del traffico;
- requisiti di scalabilità: è necessario scegliere un’architettura che possa espansioni future della rete e delle necessità a cui questa deve adempiere;
- sicurezza: è necessario scegliere un’architettura che supporti robuste misure di sicurezza e di controllo degli accessi.
Tipologie di rete (per estensione)
- LAN (Local Area Network);
- WAN (Wide Area Network);
- CAN (Campus Area Network)^[Collegamento di alcune LAN.];
- MAN (Metropolitan Area Network). Si parla anche di VPN (Virtual Private Network), che consentono di creare un tunnel sicuro con cui il traffico può viaggiare crittografato in una rete pubblica. In particolare, le VPN consentono agli utenti di collegarsi a delle reti, anche private, da remoto, come se fossero fisicamente collegati alla rete stessa ed offrono un livello di sicurezza aggiuntivo dato dalla crittografia, proteggendo i dati in transito da accessi non autorizzati su reti pubbliche. Esistono anche delle reti in cloud che offrono risorse e servizi di rete come firewall e macchine virtuali, sfruttando il cloud e non richiedendo hardware on site.
Gerarchie delle reti
In reti più piccole, di solito, si utilizza una flat network, cioè un’architettura di rete con pochi strati, che non offrono molta scalabilità o sicurezza. In contesti più grandi, tuttavia, si ha una stratificazione su almeno tre livelli:
- core layer: la backbone^[Si dice backbone una rete che ha funzione di dorsale: collega più segmenti di rete.];
- distribution layer: connette la core e il livello di accesso, distribuendo il traffico tra più LAN;
- access layer: fornisce connettività all’utente finale con accesso diretto alla rete.
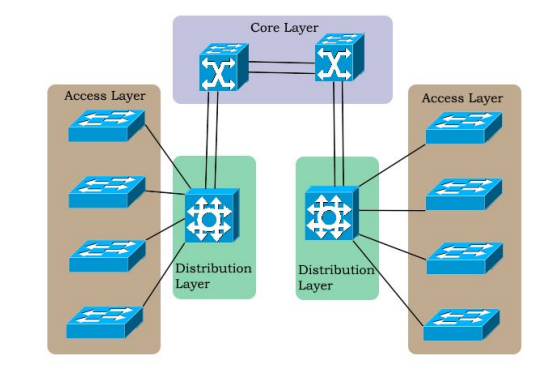
Approfondimento: CAN e gerarchia della rete
Come anticipato, una Campus Area Network consente di collegare più LAN tra di loro, utilizzando diverse tecnologie di rete (cavi ethernet, ma anche fibre ottiche e soluzioni wireless). Le CAN, inoltre, forniscono anche dei servizi centralizzati, come soluzioni di file sharing, email e tool per la gestione della rete, ma richiedono misure di sicurezza per proteggere dati sensibili. È necessario, dunque, adempiere a 4 caratteristiche chiave:
- gerarchizzazione: strutturazione delle funzionalità di rete in livelli, come appena visto;
- modularità: il design della rete prevede l’impiego di moduli containerizzati e indipendenti;
- resilienza: la rete deve sopportare guasti mantenendo le proprie funzionalità;
- flessibilità: la rete deve potersi adattare se il traffico e le necessità cambiano.
Reti virtuali
Reti virtuali - premessa: unmanaged vs managed switch
Esistono due tipologie di switch: unmanaged e managed, che offrono un diverso grado di funzionalità aggiuntive. Uno switch unmanaged è un dispositivo plug&play, con un limitato set di funzioni e praticamente l’assenza di opzioni di configurazione; sono dispositivi economici che trovano impiego in soluzioni dove la semplicità e i costi hanno la priorità (piccole reti oppure per l’aggiunta temporanea di gruppi di lavoro a reti più grandi). Di contro, gli switch managed sono altamente configurabili e consentono di implementare funzionalità come:
- VLAN: segmentazione della rete in gruppi logici per una migliore sicurezza e un maggior controllo del traffico;
- QoS;
- meccanismi di sicurezza: implementazione di una lista per il controllo degli accessi (ACL, Access Control List);
- link aggregation: aggregazione di più collegamenti fisici in un collegamento logico per avere più banda e ridondanza;
- monitoraggio e troubleshooting: gli switch managed possono fornire informazioni sulle prestazioni di rete che consentono di individuare problemi. Di contro, gli switch managed sono più costosi e risultano ideali in ambienti in cui è necessario garantire un certo livello di prestazioni e/o avere un controllo più granulare sul traffico.
Reti virtuali - Definizione
Le reti virtuali sono delle reti definite mediante software e risiedono in delle reti fisiche; il vantaggio è quello di creare segmenti di rete logici isolati che funzionano in modo indipendente dall’infrastruttura fisica di rete. Il tipico esempio di utilizzo sono le SDN (Software Defined Network), un approccio alla gestione della rete che prevede il disaccoppiamento del control plane (implementato via software) dal data plane (implementato via hardware); ciò consente di avere un controllo centralizzato dei dispositivi di rete e del traffico. Infatti, il control plane consente di realizzare via software le politiche di rete, le regole di inoltro e, più in generale, tutto il comportamento della rete, mediante un controller centralizzato, mentre il data plane si semplifica, essendo composto da dispositivi di rete fisici (switch e router) che inoltrano pacchetti sulla base delle direttive del control plane. In questo contesto, gli switch managed possono essere integrati nelle SDN, in modo che possano comunicare con il controller ed implementare la configurazione di rete virtuale a livello fisico.
Netowrk dependability
L’affidabilità di una rete dipende da 4 caratteristiche:
- reliability;
- disponibilità;
- resilienza;
- sicurezza.
Reliability
Con reliability di una rete si intende la sua affidabilità nello svolgere le funzioni per cui è designata in uno specifico intervallo di tempo. È un’indicazione della frequenza dei guasti e dell’ammontare del tempo in cui il sistema funziona correttamente, sul totale. Le metriche utilizzate sono:
- mean time between failures (MTBF)^[Può essere ricavato dal datasheet del componente. Qualora non sia espresso, si può far riferimento agli standard ricavati da apparecchiature simili, da dati storici del sistema oppure usando modelli predittivi. ]: il tempo medio tra due guasti;
- mean time to repair (MTTR): il tempo medio per riparare un guasto.
Disponibilità
La disponibilità è l’indicazione della probabilità che un sistema funzioni come previsto durante un certo intervallo di tempo. Rappresenta l’uptime (o la percentuale di tempo) in cui il sistema è operativo e accessibile e misura l’accessibilità complessiva del sistema, considerando sia interruzioni di servizio programmate (e.g. per manutenzione), sia quelle non programmate dovute a guasti. Le metriche utilizzate sono:
- uptime: percentuale del tempo in cui il sistema è operativo;
- downtime: percentuale del tempo in cui il sistema non è disponibile.
SLA - SLO
SLA
Con SLA (Service Level Agreement) si indica un documento ufficiale che delinea dei livelli minimi di servizi attesi, convalidati dal cliente e dal fornitore di servizi. Tipicamente, include:
- metriche specifiche di servizio: uptime, tempo di risposta, tasso di errore;
- valori target: il livello di performance specificato per ogni metrica, su cui ambo le parti convengono;
- rimedi: specifiche su rimedi qualora non si raggiungano i valori target.
SLO
Con SLO (Service Level Objective) si intende un target interno, contenuto in un SLA, che si concentra su una specifica metrica di servizio. Rappresenta un obiettivo interno al fornitore di servizi per raggiungere il valore target contenuto nello SLA. Questi non vengono comunicati direttamente al cliente ma servono al fornitore di servizi per riuscire a garantire il servizio delineato nello SLA.